このページではFREDに関する基本情報とデータの検索方法・取得方法について紹介します。データ取得には、pythonライブラリのpandas-datareaderを利用します。
FREDとは
国家、各国、公共、個人が評価した数十万からなる経済時系列データから成るオンラインのデータベースです。セントルイス連邦準備銀行(Federal Reserve Bank of St. Louis)の部門がリサーチ部門が作成・管理しています。(公式ページ)。
データの探し方
何十万もの経済データから目的に沿ったデータを見つける必要があります。データの探し方は主に次の4つがあるようです。
- 検索バーからの検索
- カテゴリから絞り込む
- リリース情報から見つける
- タグから見つける
検索バーからの検索
検索バーから検索する場合は、画面右上の検索バーにキーワードを入力することでデータを見つけることができます。詳細な手順はこちらをご確認ください。
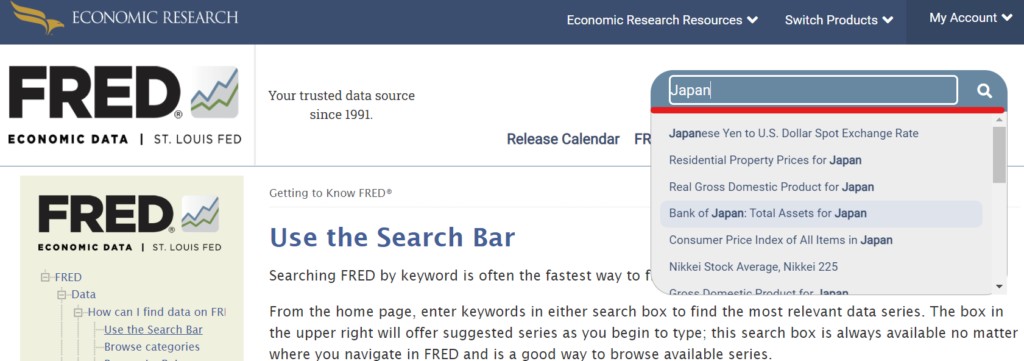
キーワードを入力すると候補が出てくるので、欲しいデータがあれば直接選択するとデータに関するページに移動します。
(例) Nikkei Stock Average, Nikkei 225を選択した場合
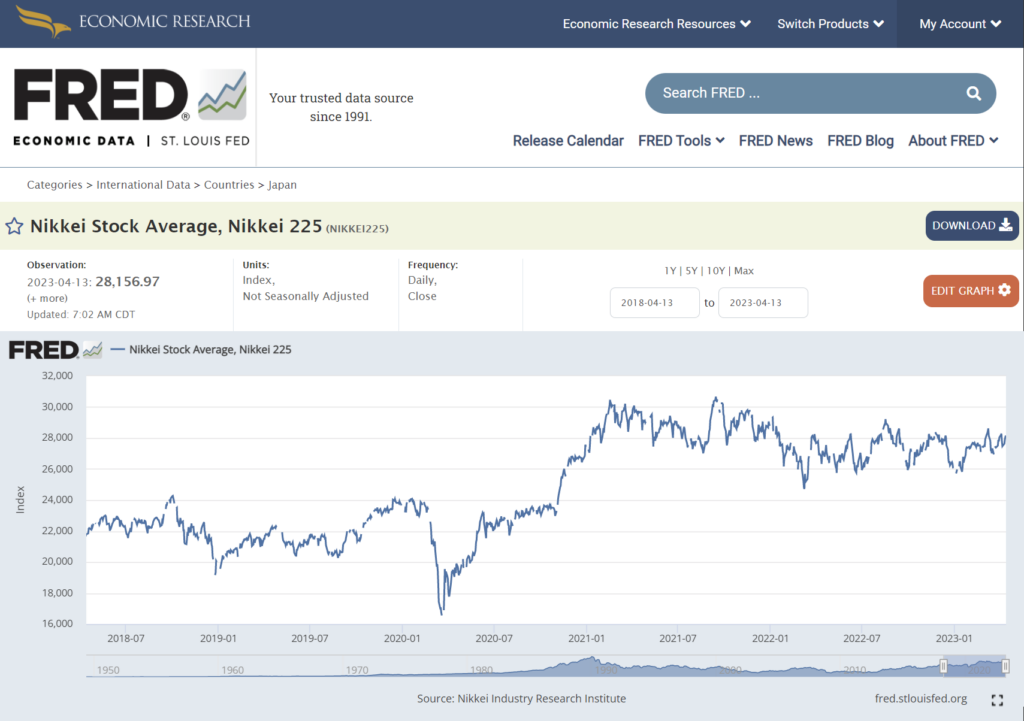
ページ下部の”NOTES”には、データソースやデータの頻度なども書かれております。
(例) ”Japan”を入力し、[Enter]を押した場合
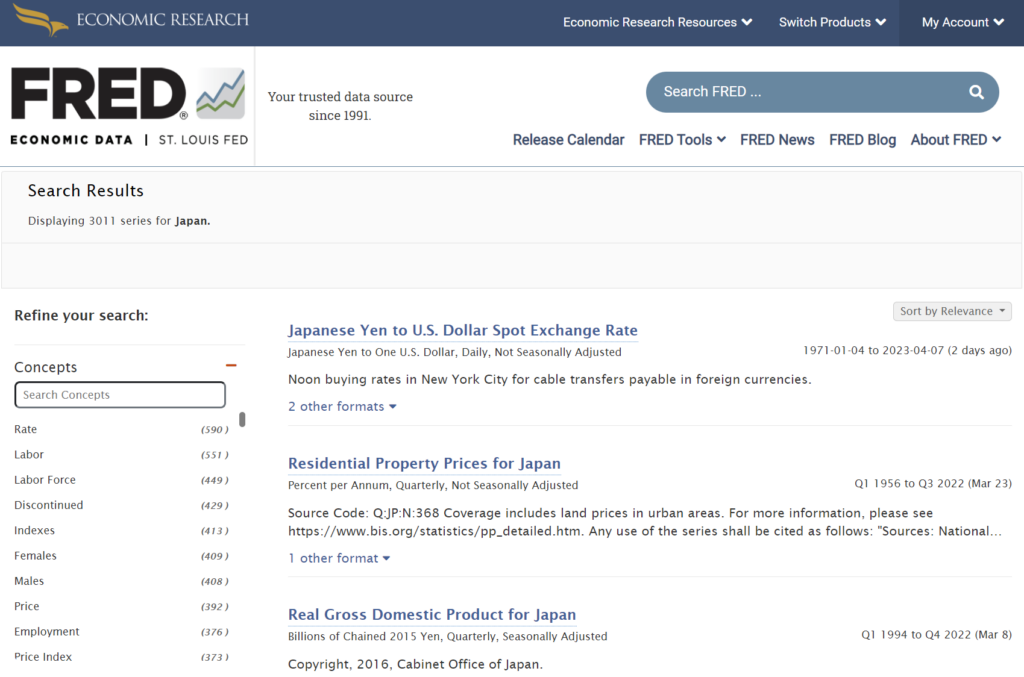
検索結果が一覧で表示されます。この中から欲しいデータを見つけることもできます。
カテゴリから絞り込む
トップページの”Brose Data By”にある”Category”からカテゴリによる検索が可能です。
カテゴリは以下の通りです。
- Money, Banking, & Finance :金融関連(金利、為替、マネタリーベース等)
- Population, Employment, & Labor Markets :人口、雇用、労働市場
- National Accounts: 国民経済計算(GDP、GNP等)
- Production & Business Activity:
- Prices :コモディティ、輸出入関係指標、
- International Data:各国のデータ
- U.S. Regional Data:米国の各州のデータ
- Academic Data:アカデミックデータ
リリース情報から見つける
トップページの”Brose Data By”にある”Release”から公表済みのデータを見つけることができます。
データの精通している場合は効率よく見つけられるかもしれないですが、あまり使い道はなさそうな印象です。
トップページの”Release Calendar”からはカレンダーから公表予定&公表済みのデータを見つけることができます。
こちらの方がデータを見つける場合は、使い勝手が良さそうです。
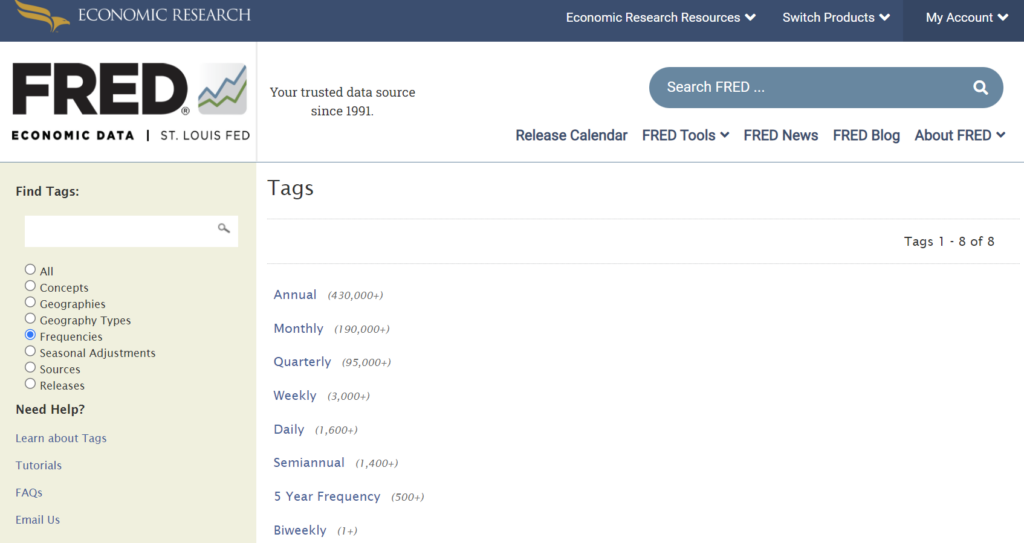
タグから見つける
こちらのページからデータに紐づいているタグからデータを探索することもできます。
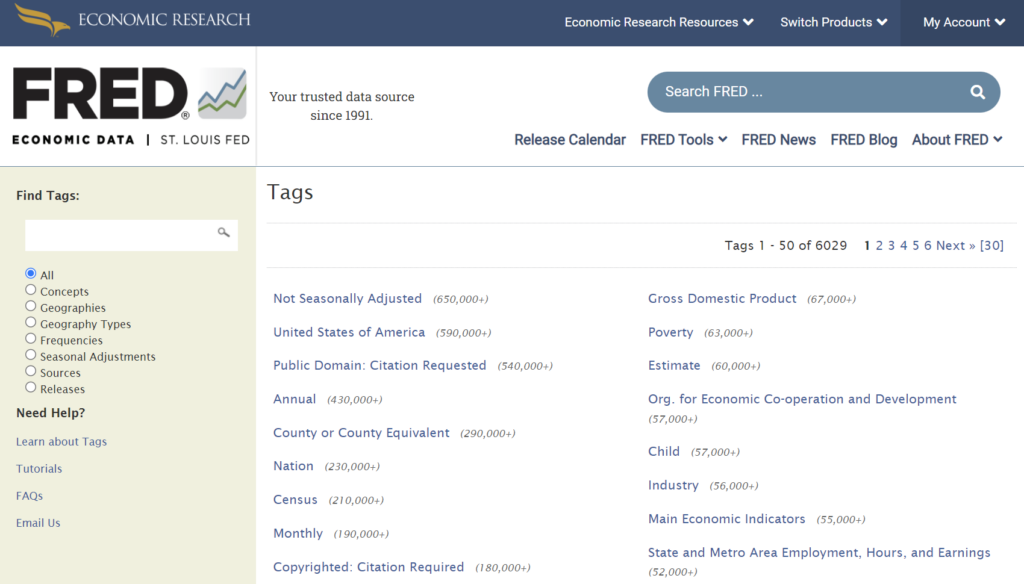
タグは、”All”(すべて)、”Concepts”(コンセプト)、”Geographies”(地域別)、”Geographies Types”(地域タイプ)、”Frequencies”(更新頻度)、”Seasonal Adjustment”(季節調整の有無)、”Sources”(データソース)、”Releases”(公表元)に分かれています。
Frequenciesによる検索は、時系列モデルを作る場合のデータ探索に利用できそうです。
FREDデータの取得方法
ここからは欲しいデータを見つけた場合の取得方法について紹介します。データの取得には、pythonラライブラリのpandas-datareaderを利用します。
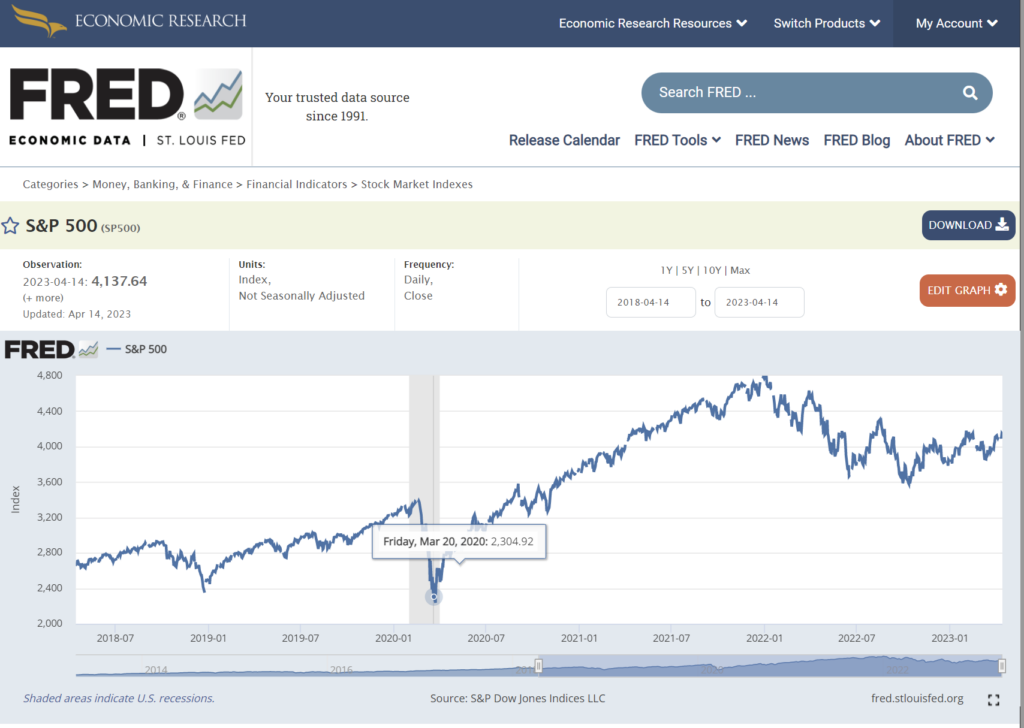
ここでは、S&P500のデータを例に紹介していきます。
まず、データを取得には各データのコード(ティッカー)が必要です。そこでS&P500のページに行き、S&P500のティッカーコードを特定します。基本的には、データ名の後ろに括弧で描かれているコードがティッカーコードになります。S&P500の場合は、”SP500″がティッカーコードになります。
ティッカーコード(Symbol)が取得出来たらpandas_datareader.fred.FredReader()を利用してデータを取得します。引数に上で取得したSymbolを指定するだけでデータを取得できます。オプションで開始時点、終了時点なども指定することができます。
以下、pandas-datareaderを用いたS&P500のデータ取得サンプルになります。

コメント