
Kaggleで”Jane Street Market Prediction”というマーケット予測に関するコンペが1か月前くらいから開催されています。つい最近それを知ったので、勉強がてらKaggleに挑戦してみようと思います。
※本記事は、公開しているNotebookをまとめたものとなっております。
Kaggle APIを使用してデータを取得してみる
アカウントのサインインとコンペへの参加が完了したら、データセットを取得する必要があります。
データセット取得方法は、手動かAPIを利用することでできます。
APIでデータ取得をするのはどうやるのか気になったので以下にまとめておきます。
基本的には、ここを見ればできると思います。
ちなみに、手動でダウンロードする場合は、以下のコンペページの”Data”から[Download All]ボタンを押せばできます。
1. ライブラリのインストール
pip install kaggle をコマンドラインから実行し、kaggleのライブラリをインストールします。
2. APIのトークンを取得する
Kaggleのアカウント画面から[Account]タブを選択する。
API欄の[Create New API Token]をクリックすると、トークン(kaggle.json)のダウンロードが始まり、トークンが入手できます。
3. トークンの設定
ダウンロードしたトークンを所定のフォルダに配置します。
<Windowsの場合>
C:\Users\<Windows-username>\.kaggle\kaggle.json
<Mac / Linuxの場合>
~/.kaggle/kaggle.json
<WSL / WSL2の場合>
/home/<username>/.kaggle/kaggle.json
ちなみに私の環境はWSL2なので3つ目のパターンでした。
4. 権限設定と動作確認
試しに動作確認として、コマンドラインに”kaggle -h”と入力してみると以下のようにアクセス権限についてお叱りを受ける。
(py38) <username>@MyComputer:/mnt/c/Users/<username>$ kaggle -h
Warning: Your Kaggle API key is readable by other users on this system! To fix this, you can run ‘chmod 600 /home/<username>/.kaggle/kaggle.json’
ということで、指示通り、以下のコマンドを入力し、ファイルに権限を付与する。
chmod 600 /home/<username>/.kaggle/kaggle.jsonここのコマンドは、それぞれのOSでの警告メッセージに応じて変更してください。
再度、コマンドラインに”kaggle -h”と入力して何も怒られなければ設定は完了。
5. データセットの取得
kaggleライブラリにはいろいろな機能があることは、”kaggle -h”コマンドからも読み取れますが、今回はデータセット取得に留めておきます。
コマンドは、コンペのトップページに以下が書いてあるのでそれをそのまま使用しました。

データセットは、保存先を指定しない場合はカレントディレクトリに保存されます。
保存先を指定する場合は、’-p <保存先のパス>’を追記することで可能です。
今回のデータは、2.63Gもありなかなか時間がかかります。
手動で取得するのと大差ないと思われる方もいると思いますが、kaggleライブラリにダウンロード以外にもサブミッション機能やリーダーボード情報を取得できるなど便利な機能もあるので設定しておいて損はないと思います。
データについて見てみる
取得できたzipファイルを解凍すると以下のデータがあります。
今回のデータは、世界的に主要なある株式?(“a major global stock exchange”)のデータとなっています。
- example_sample_submission.csv
- example_test.csv
- features.csv
- train.csv
example_sample_submission.csv
ファイルの中身は以下となっています。
“ts_id”は時系列の順番でIDを割り当てています。
“action”は1:トレードを実行、0:見送りを表しています。
この例では、すべて”action”は1となっている。
kaggleに提出するときは、このデータ構造で提出する必要があります。

example_test.csv
ファイルの中身は以下の通りです。
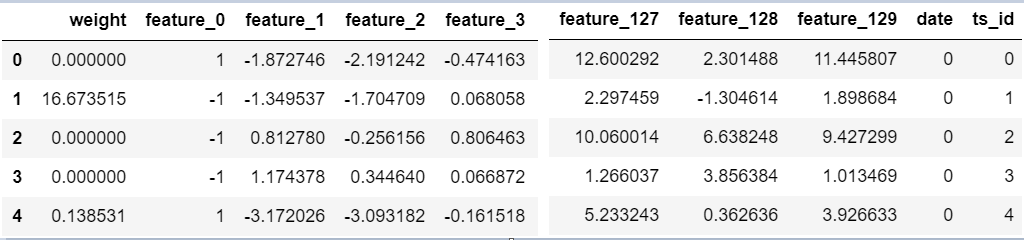
テストデータ用のデータセットとなっています。
“weight”は後述します。
“feature_X”は匿名の説明変数となっており、130個あります。
“date”は取引日を表しています。
テストデータでは”date”は0~2となっているので、3日間のデータということになります。
モデルのテストはこのデータセットを用いて行い、この予測結果を提出します。
モデルの学習では、使用してはいけない点に注意する必要があります。
features.csv
ファイルの中身は以下の通り。
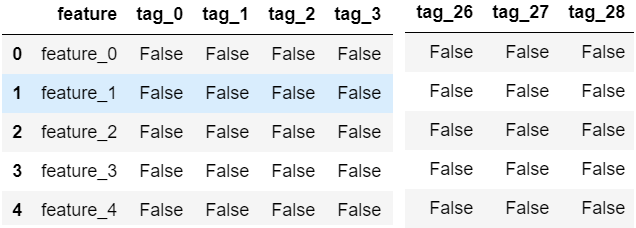
各行に匿名変数”feature_X”に対応しており、各列に匿名変数のメタ情報として”tag_X”が格納されています。
メタ情報は28個からなっており、値は2値(TRUE/FALSE)となっています。
情報が非公開過ぎて何を表しているのかわからないです…。
28個のカテゴリがあって、各説明変数は、それぞれのカテゴリに属しているか否かといった感じに見えます。
train.csv
ファイルの中身は以下の通り。
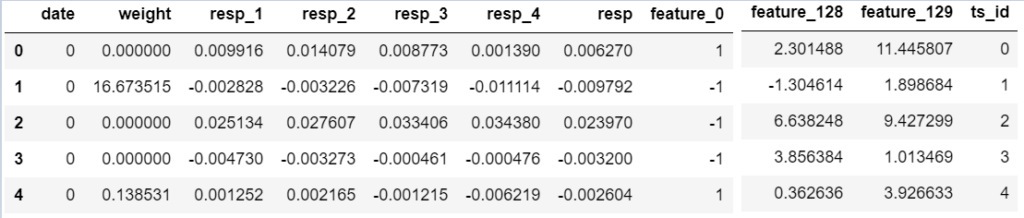

データ数は、2,390,490個あります。
“date”は500まであることから500日分のデータと思われます。
2,390,490 ÷ 500(日) ÷ 24(h) ÷ 60(min) ≒ 3.3個/分であることから、約20秒ごとのデータに思えます。
“weight”と”resp”はそれぞれの取引のリターンを表しています。
resp_{1,2,3,4}は、異なる時間軸におけるリターンです。
おそらく、これは取引終了の期間幅を表しており、例えば、取引開始後の{1時間後, 6時間後, 12時間後, 24時間後}といった意味合いだと思われます。
尚、テストデータにはresp_{1,2,3,4}は含まれていないです。
”weight”がゼロのものは、補完のために意図的にデータセットに加えたもので、スコア評価には組み込まれないと説明にありました。
“weight”の意味については、把握しきれていないですが、0と0以外について特徴を見ておく必要がありそうです。
“wight”がゼロであるものは、全体の17%程度でした。
評価対象外ということからデータセットから除外してみてもよいのかもしれないです。
まとめ
今回は、Kaggleの【Jane Street Market Prediction】に参加するにあたり、データ取得方法と取得したデータについて簡単に見てみました。
データを見たもののまだ読み解けないのでより細かく見ていく必要がありそうです。
次回は、データの特徴について細かく見ていく予定です。
予測精度の高いモデル構築には、まずはデータの特徴について正確に把握しておくことが肝心なのでこの辺はしっかりやっていきたいと思います。


コメント