
前回の記事はAPIからのデータ取得方法の確認とデータセットについて確認を行いました。
Kaggleを触り始めて、ローカルのPCにデータを置いておく必要がないことを知ったので、備忘録として記事にしておきます。
<追記>
メモリやCPU利用制限など制約があり、何も考えずにいるとメモリー不足エラーになること多々ありました。dfの型を適切に設定することである程度メモリを節約できるみたいです。
詳細は次の記事に掲載します。
手順
1. KaggleのNotebooksのページから[+ New Notebook]ボタンを押します。

2. Jupyter Notebookが立ち上がります。
3. 右側の[+Add data]を選択します。
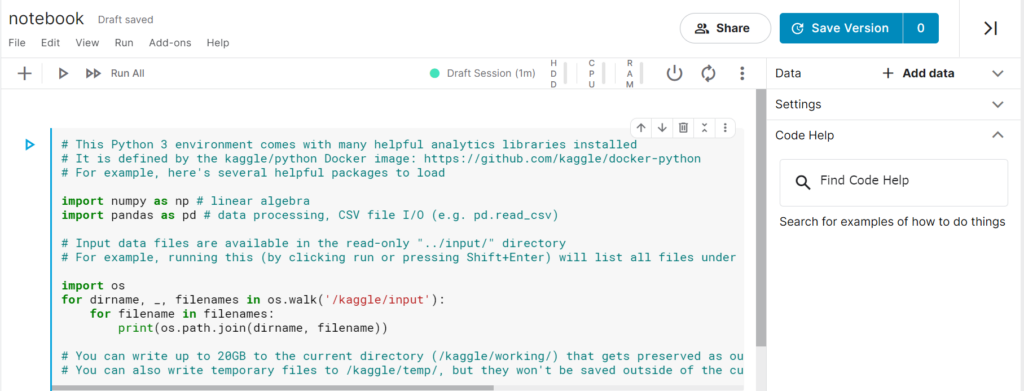
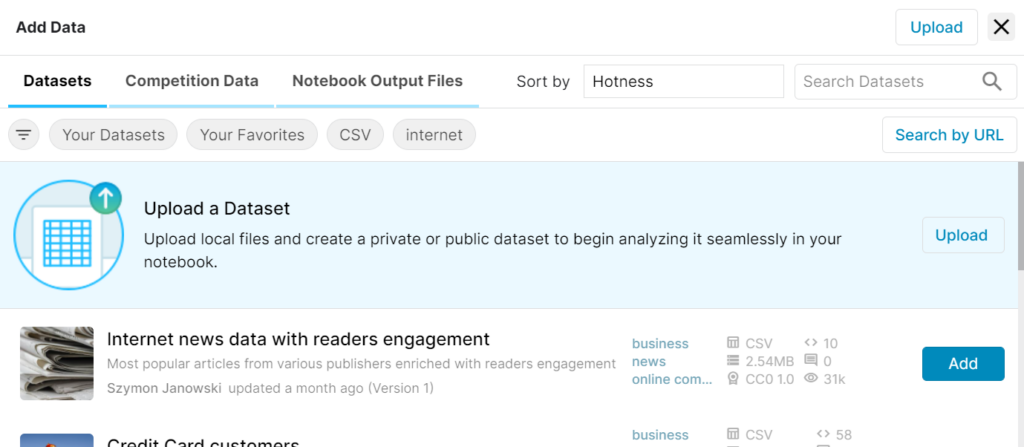
4. Kaggleのクラウド上で使用したいデータセットを選択します。
今回は、”Jane Street Market Prediction”を追加したいので、”Competition Data”を選びました。
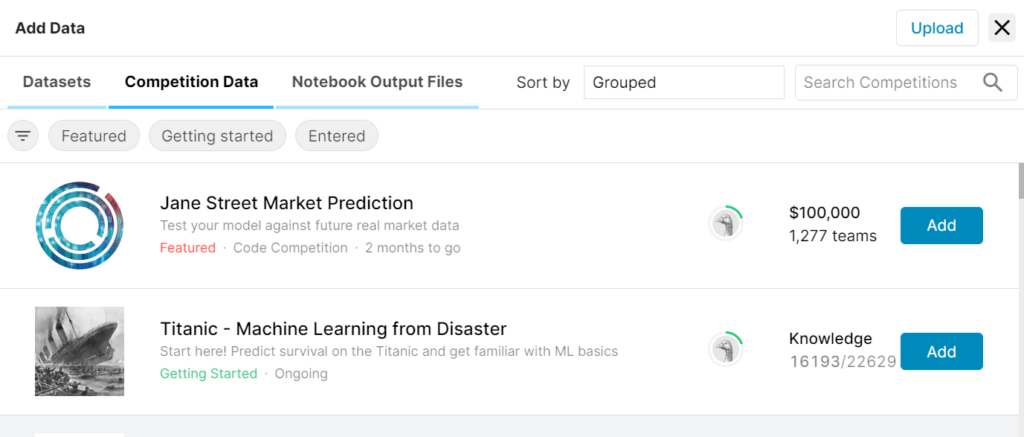
5. “Jane Street Market Prediction”が見つけたら、その横にある[Add]を押します。
6. 以上でKaggleのJupyter Notebook上でデータセットを読み込むことができるようになります。
パスの確認は、Jupyter Notebookの1段目に書かれているコードをそのまま実行するだけです。
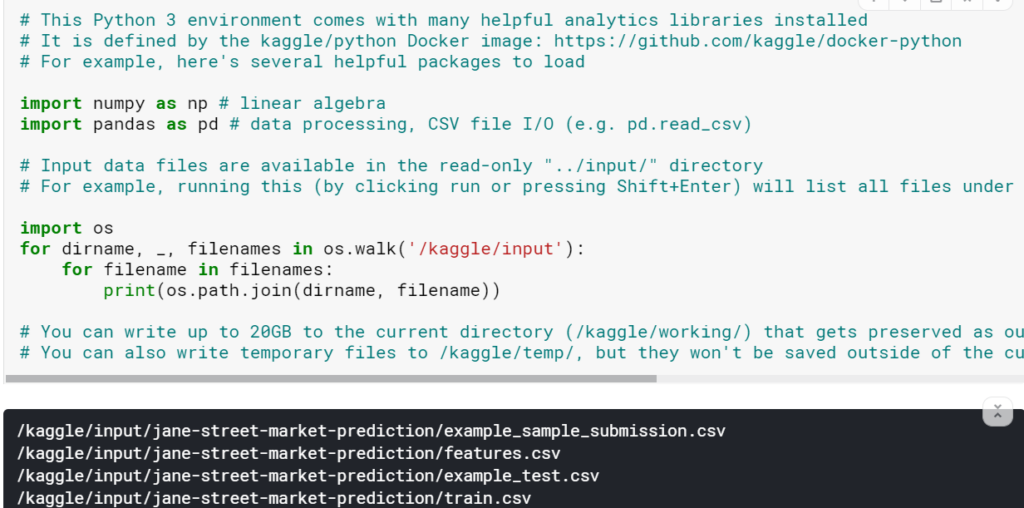
7.データセットは、上記で表示されたファイルパスをpandasでそのまま読み込むことができます。
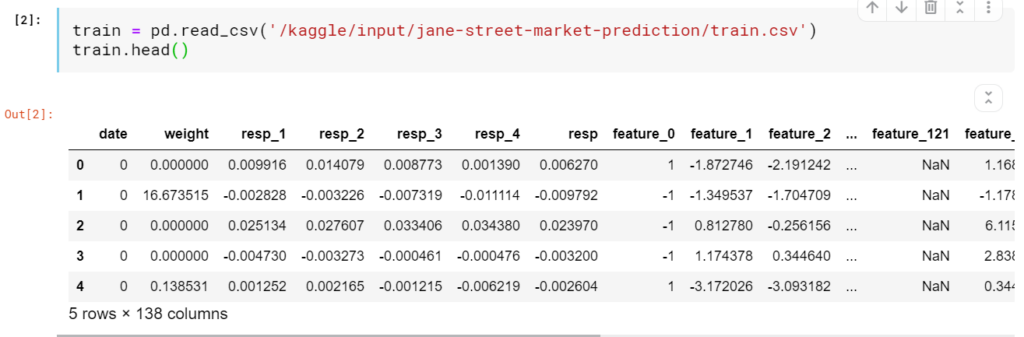
以下にtrain.csvを読み込んだ例を載せておきます。(容量が大きいので少し時間がかかります。)
8. 分析・モデル構築
まとめ
Kaggle上だけで分析を済ませたいならこれだけで十分そうです。
今回のコンペのデータセットは2.63Gもあり、ローカルには置きたくないと思ってたのでいたので助かりました。
ただ、ネットワークにつながっていることが必須なので、ネットワーク環境のない外出先では利用できないのが難点です。
KaggleのNotebookではGPUも使えるので、簡単な開発はKaggle上で行うのも手段としてありだと思います。

コメント