
前回の記事は、PytorchでCNN(1次元畳み込み)を用いたモデルとして、単純な構造のCNNとTCN(Temporal Convolutional Network)を構築してみました。
CNNのスコアが1745.844でTCNが2091.370で、若干ですが、TCNの方が精度が良いという結果が得られました(スコアはかなり悪い)。
今回は、TCNを改良してスコアアップを図ってみたので、簡単に記事にしておきます。
現時点では、TCNが5785.452まで向上しました。
※本記事は、公開しているNotebookをまとめたものとなっております。
・CNNの学習に関するNotebook ⇒ こちら, 推論に関するNotebook ⇒ こちら
・TCNの学習に関するNotebook ⇒ こちら, 推論に関するNotebook ⇒ こちら
変更①全結合層の追加
最初のモデルでは、TCN-全結合層×1-出力層(全結合層)の構成をしておりました。
出力層の前の全結合層を追加することで精度向上が見られました。
- TCN – 全結合層×1 – 出力層(全結合層):2091.370
- TCN – 全結合層×2 – 出力層(全結合層):5785.452
- TCN – 全結合層×3 – 出力層(全結合層):5132.795
上記の結果から、全結合層は出力層を含めて、3層が良いみたいです。
単純に層を増やすだけでは、精度向上に限界があるようです。
変更②ネットワーク構成の修正
TCNのネットワークを丁寧に書くようにしました。
以下の図は、ネットワークをprint出力したものになりますが、fc2~fc3でドロップアウト層やバッチノーマライゼーション層が省略されているのがわかります。
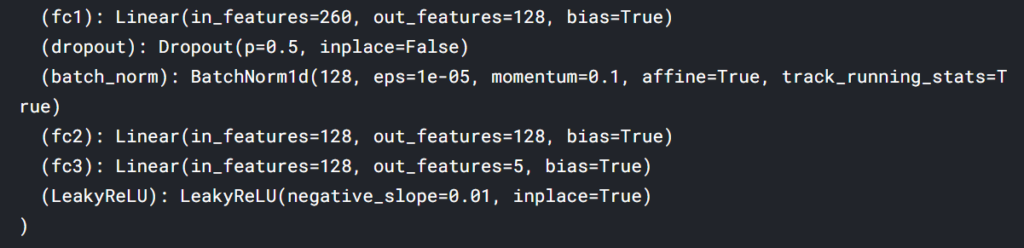
これは、横着してfc1で利用しているドロップアウト層やバッチノーマライゼーション層をそのままfc2やfc3に適用してしまっているためです。(もしかしたら、Pytorch内でも共通の認識をされている?)
これをきちんと分けて、以下のようになるように修正しました。
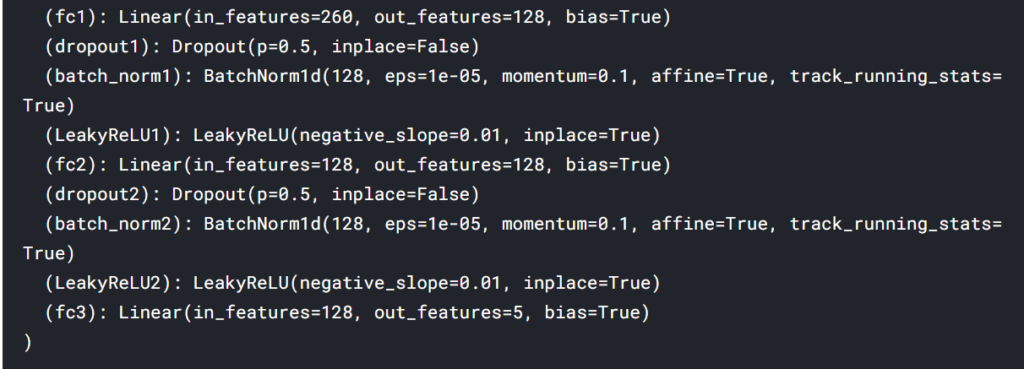
変更③ 期間幅(window_size)を変えてみる
最初のモデルでは、一旦、期間幅を20としてました。
この期間幅のサイズに応じで、モデルはどれだけ過去のデータを参考にするのかを決めることができます。
今回は、この期間幅を短期(window_size=5)と長期(window_size=100)の場合で試してみました。
結果は、以下の通り。
- 短期(window_size=5):6951.875
- 中期(window_size=20):5785.452
- 長期(window_size=100):5227.883
上記の結果から、期間は短いほうが良いことがわかりました。
長期の時系列データとして扱わない方が精度が良くなるのかもしれません。
(追記)
さらに期間を短くしてみた場合(window_size=3)、スコアは0.000となりました。
出力結果を見るとaction=1に偏っていたことから過学習の可能性がありました。
変更④ 学習データを選別する
今回のコンペでは、weightが0の予測値はスコア計算に利用されません。
上で作成してきたモデルの学習データにはweight=0のものを含めていました。
そこで、weight=0の場合は、バッチに含めないように処理を修正してみました。
期間幅が5のモデルで比較を行った結果が以下の通り。
- weight=0を含む場合:6951.875
- weight=0を含まない場合:5559.145
スコアが良くなると思っていただけに残念な結果になりました。
時系列でweight=0を含む場合があることが多少作用したのでしょうか。原因は、わかりません。
主なコードの変更点としては、
- Dataset Classでweightを返すようにしたこと
- BatchSamplerクラスをオーバライド
- DataLoaderでは新しく定義したBatchSamplerを用いてバッチデータを作成する
詳細については、Notebookを見てください。
以下に変更したコードを参考程度に載せておきます。
from torch.utils.data import Dataset
from torch import nn
class JSMP_Dataset(Dataset):
def __init__(self, file_path, window_size):
# valiables
self.file_path = file_path
self.window_size = window_size
# read csv
train = pd.read_csv(file_path)
# pre processing
train = train.query('date > 85').reset_index(drop = True)
#train = train[train['weight'] != 0]
train.fillna(train.mean(),inplace=True)
train['action'] = ((train['resp'].values) > 0).astype(int)
resp_cols = ['resp_1', 'resp_2', 'resp_3', 'resp', 'resp_4']
self.features = [c for c in train.columns if "feature" in c]
self.f_mean = np.mean(train[self.features[1:]].values,axis=0)
self.X_train = train.loc[:, train.columns.str.contains('feature')].values
self.y_train = np.stack([(train[c] > 0).astype('int') for c in resp_cols]).T
self.X_train = torch.from_numpy(self.X_train).float()
self.y_train = torch.from_numpy(self.y_train).float()
self.X_weight = torch.from_numpy(train['weight'].values)
# reduce memory
del train
gc.collect()
def __len__(self):
return len(self.X_train) - self.window_size
def __getitem__(self, i):
weight = self.X_weight[i + self.window_size - 1]
data = self.X_train[i:(i+ self.window_size), :]
label = self.y_train[i + self.window_size - 1]
return weight, data, labelfrom torch.utils.data import RandomSampler
from torch.utils.data import BatchSampler
class NonZeroWeightBatchSampler(BatchSampler):
def __init__(self, batch_size, dataset):
self.sampler = RandomSampler(dataset)
self.batch_size = batch_size
self.dataset = dataset
def __iter__(self):
batch = []
for idx in self.sampler:
# avoid using weight = 0 data
if self.dataset[idx][0].item() == 0:
continue
else:
batch.append(idx)
if len(batch) == self.batch_size:
yield batch
batch = []
if len(batch) > 0:
yield batch# make DataLoder
train_dataloader = torch.utils.data.DataLoader(train_ds, batch_sampler=batch_sampler_train)
valid_dataloader = torch.utils.data.DataLoader(valid_ds, batch_sampler=batch_sampler_valid)
# dict
dataloaders_dict = {'train': train_dataloader,
'val' : valid_dataloader}まとめ
今回は簡単なTCNモデルの改良をしてみました。
ここまでの結果から、window_size=5で全結合層が3層(出力層を含む)がスコア6951.875と一番良かったです。
ここからさらに改善をしていくとなると、アンサンブル学習にするとかになるのでしょうか。
今回は、検証データの損失値が最小となるモデルを最良のモデルとしていたので、Accuracyが最高の場合を最良のモデルにした場合やそれら二つの平均を予測値とするなど改良はできそうな気がします。


コメント