
今回も「Python3ではじめるシステムトレード ──環境構築と売買戦略」で学んだことを自分なりに整理します。今回のテーマは「マクロ変数」です。
これまでは日経平均株価にのみ着目して分析してきました。
今回は、日経平均株価とマクロ変数の関係を見ていきます。
使用するマクロ変数は、労働人口、国内総生産にします。
データ取得は、pandas-datareaderのFredより取得します。
国内総生産は、ドル建てになっているため、円換算にするためにドル円の為替レートも併せて使用します。
マクロ変数の関係性について
まずは、今回使用する労働人口と国内総生産について調べてみます。
労働人口は経済の原動力であり、国内総生産はその結果です。
2変数について回帰分析してみた結果は以下の通りです。
import pandas_datareader as pdr
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
# データ取得
start = '1971/12/31'
end = '2016/8/31'
WorkPop = pdr.DataReader('LFWA64TTJPM647S', 'fred', start, end).dropna() # 労働人口(月次データ:1972/1/1, 1972/2/1,...)
GDP = pdr.DataReader('MKTGDPJPA646NWDB', 'fred', start, end).dropna() # 国内総生産(年次データ:1972/1/1, 1973/1/1)
fx = pdr.DataReader('DEXJPUS', 'fred', start, end).dropna() # ドル円為替レート(日次データ:1971/12/31, 1972/1/3, ...)
# GDPに期間を合わせる(年次にする、日付はすべて年末にする)
GDP = GDP.resample('A').last().dropna() # 1972/1/1⇒1972/12/31
WorkPop = WorkPop.resample('A').last().dropna() # 1972/12/1⇒1972/12/31
fx = fx.resample('A').last() # 1972/12/29⇒1972/12/31
# GDPを円換算
GDP_J = GDP.MKTGDPJPA646NWDB * fx.DEXJPUS
# 対数変換
GDP_J = np.log(GDP_J).dropna()
WorkPop = np.log(WorkPop).dropna()
# 回帰分析
x = sm.add_constant(WorkPop)
model = sm.OLS(GDP_J, x)
result = model.fit()
print(result.summary())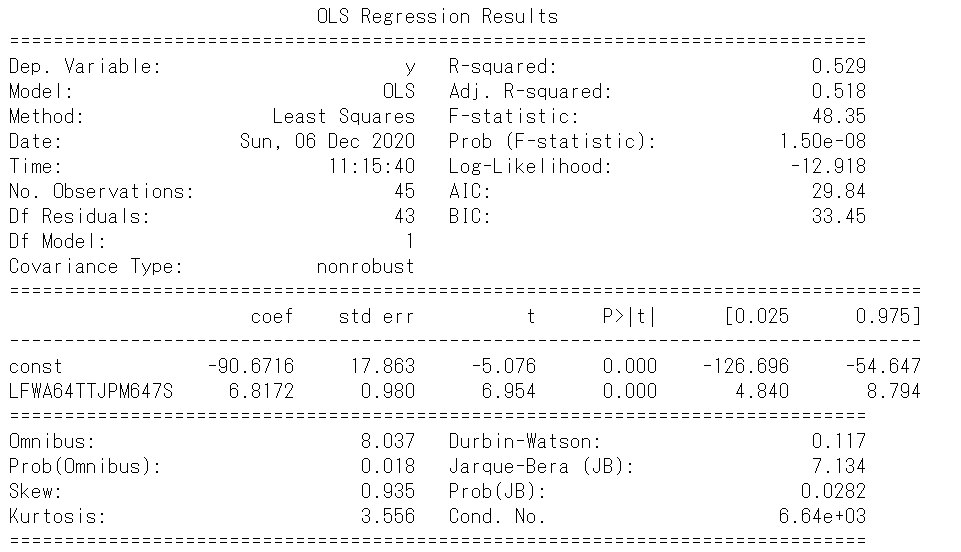
切片、回帰係数ともにp値がゼロとなっているため意味のある変数となりました。
また、決定係数は0.529とそこそこ高い値となりました。
グラフを書いてみると、以下の通りです。
# グラフを書く
f, ax = plt.subplots() # 2軸グラフ
# 1軸目
ax.plot(GDP_J, label='GDP', linestyle='--')
result.fittedvalues.plot(label='fitted', style=':', ax=ax)
ax.set_ylabel('log GDP')
ax.legend(loc='lower right')
# 2軸目
ax2 = ax.twinx()
ax2.plot(WorkPop, label='WorkPop')
ax2.set_ylabel('log WorkPop')
ax2.legend(loc='upper left')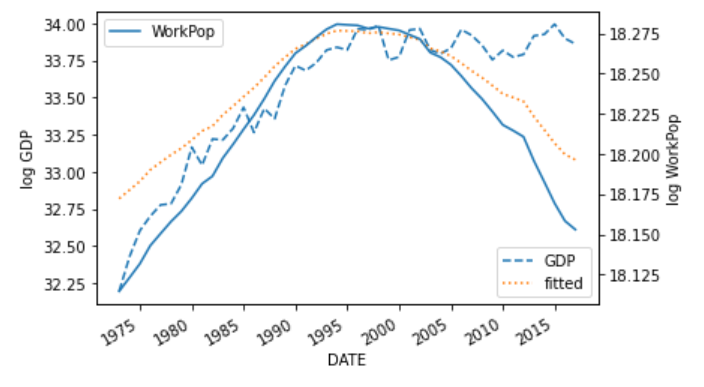
グラフを見てみると、2000年以降は、期待値は実現値をうまく説明できていないです。
労働生産性のような別の要素が影響を与えているのかもしれないです。
次に残差を確認します。
一般的に複数の非定常な時系列を最小二乗法を用いて回帰する際には、関係のない2つの変数間の回帰係数が有意な推定値をもつと判断されてしまう可能性があります。
これを見せかけの回帰と呼びます。
日経平均株価、国内総生産、労働人口はランダムウォークであるので見せかけの回帰については常に頭に置いておく必要があります。
# 残差のヒストグラムを描く
result.resid.hist(label='residual')
plt.xlabel('residual: GDP vs Work Population')
plt.ylabel('frequency')
plt.legend(loc='upper right')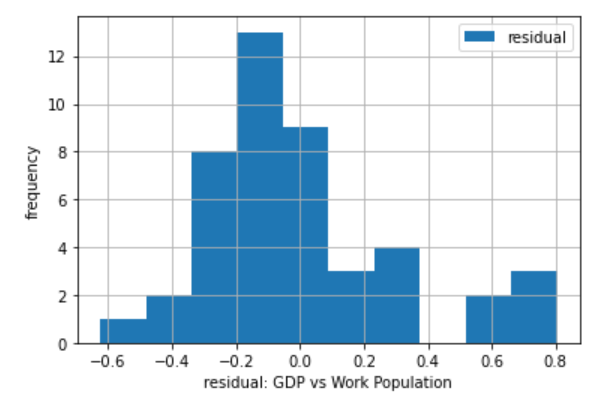
直感的には、残差は正規分布とみなせるような気もしますが、標本数が多くない為、Jarque-Bera(JB)の正規性の検定を行ってみます。
Jarque-Bara検定
JB検定では、標本数が\(n\)の残差からその歪度(\(S\))と尖度(\(K\))を求め、次の検定統計量を算出し、残差の正規性を検定します。
$$JB = n [ \frac{S^2}{6} + \frac{(K-3)^2}{24}]$$
統計量は自由度2の\(\chi^2\)分布に従います。
帰無仮説は残差の正規性であり、p値(両側検定)が十分に小さければ帰無仮説は棄却されます。
Pythonのstatsmodel.OLSのsummary()にはJarque-Bera(JB)が含まれています。
上で載せたサマリーを見てみると、p値は0.0282と小さいです。
したがって、残差は正規分布に従っているとは言えないです。
マクロ変数による多変量解析
次に、日経平均株価を被説明変数、労働人口と国内総生産を説明変数として多変量解析を行ってみます。
コードは、以下の通りです。
# データ取得
N225 = pdr.DataReader('NIKKEI225', 'fred', start, end).dropna()
ln225 = np.log(N225)
# 日次⇒年次
ln225 = ln225.resample('A').last().dropna()
# OLS
x = pd.concat([WorkPop, GDP_J], axis=1)
x.columns = ['WorkPop', 'GDP']
x = sm.add_constant(x)
y = ln225
model = sm.OLS(y, x)
result = model.fit()
print(result.summary())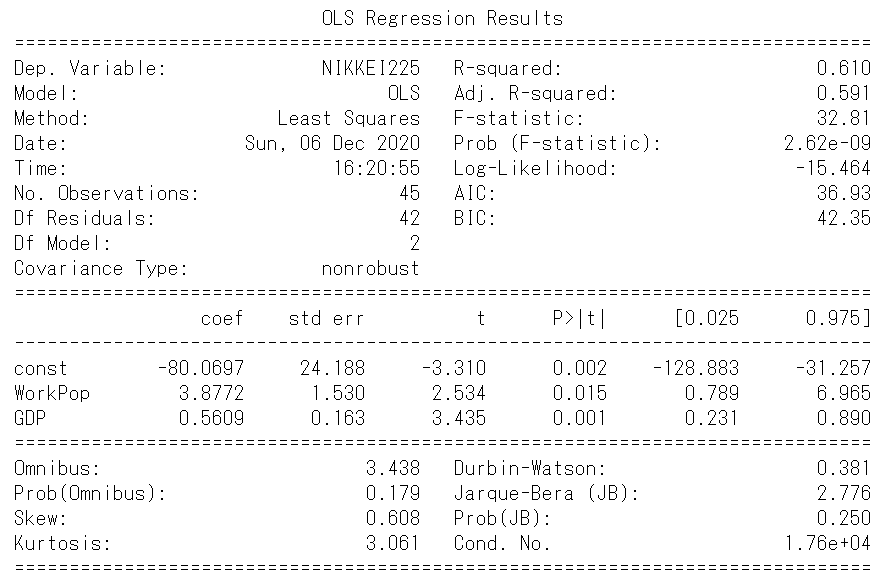
\(R^2\)は0.610であり、それぞれの回帰係数のp値はどれも1%未満です。
また、JBのp値は0.250となりました。
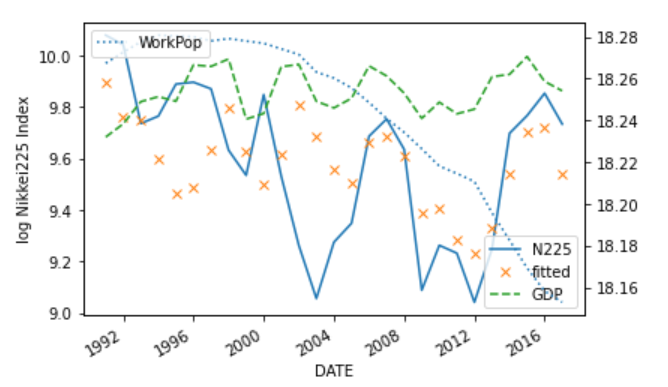
次に、日経平均株価の対数と期待値をプロットして、モデルの期待値がどれほど実際の指数を説明できているかを見てみます。
# グラフを書く
f, ax = plt.subplots() # 2軸グラフ
# 1軸目
ax.plot(ln225, label='N225')
result.fittedvalues.plot(label='fitted', style='o', ax=ax)
ax.plot(x['GDP']-24, label='GDP', linestyle='--') # 調整
ax.set_ylabel('log Nikkei225 Index')
ax.legend(loc='lower right')
# 2軸目
ax2 = ax.twinx()
ax2.plot(x['WorkPop'], label='WorkPop', linestyle=':')
ax2.legend(loc='upper left')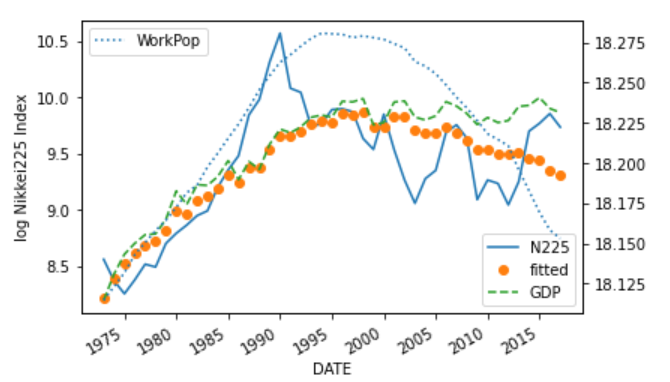
上図から以下が読み取れます。
- バブル成長期に日経平均株価はオーバーシュートし、バブル崩壊により期待値に接近している
- バブル崩壊後には米国のインターネットバブル崩壊、日本の第三次平成不況期に期待値を下方にオーバーシュートし、その後回復している
- リーマンショックで期待値を下回る様子が見られる
JBのp値は0.250と正規分布でないとは言い切れない状態です。
そこで、目視により残差を確認するため、以下を実行してみます。
# ヒストグラム:残差
result.resid.hist(label='residual')
plt.xlabel('residual')
plt.ylabel('frequency')
plt.legend(loc='upper right')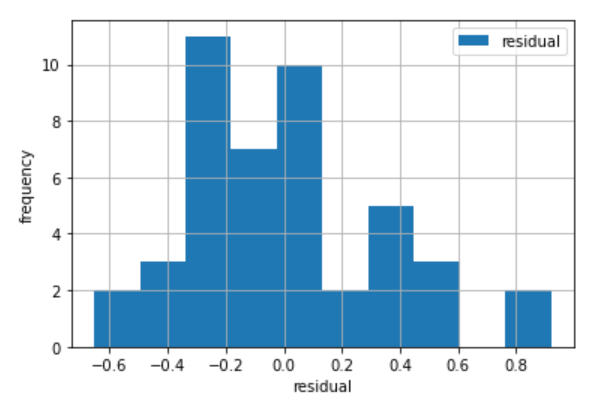
上図を見ると正規分布とは言えないように思えます。
ここまで見てきた通り、日経平均株価、国内総生産、労働人口がバブル崩壊を機に上昇から下落に転じた様子が見られました。
この様子を確かめてみるために、バブル崩壊前と崩壊後の2つの時期に分けて分析をしてみます。
バブル崩壊前
# バブル崩壊前
x_before_bubble = x[:'1990/1/1']
y_before_bubble = ln225[:'1990/1/1']
model = sm.OLS(y_before_bubble, x_before_bubble)
result = model.fit()
print(result.summary())
# グラフを書く
f, ax = plt.subplots() # 2軸グラフ
# 1軸目
ax.plot(y_before_bubble, label='N225')
result.fittedvalues.plot(label='fitted', style='o', ax=ax)
ax.plot(x_before_bubble['GDP']-24, label='GDP', linestyle='--') # 調整
ax.set_ylabel('log Nikkei225 Index')
ax.legend(loc='lower right')
# 2軸目
ax2 = ax.twinx()
ax2.plot(x_before_bubble['WorkPop'], label='WorkPop', linestyle=':')
ax2.legend(loc='upper left')
# ヒストグラム:残差
result.resid.hist(label='residual')
plt.xlabel('residual')
plt.ylabel('frequency')
plt.legend(loc='upper right')
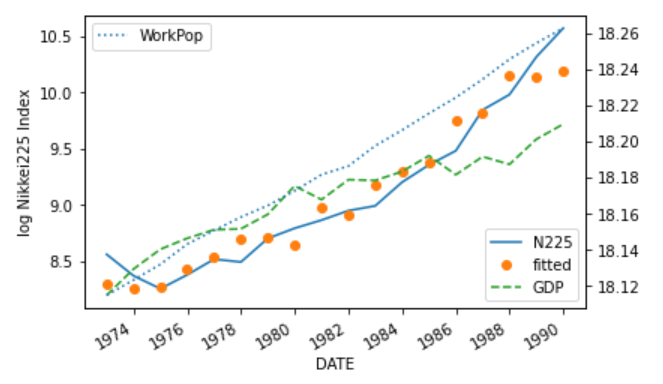
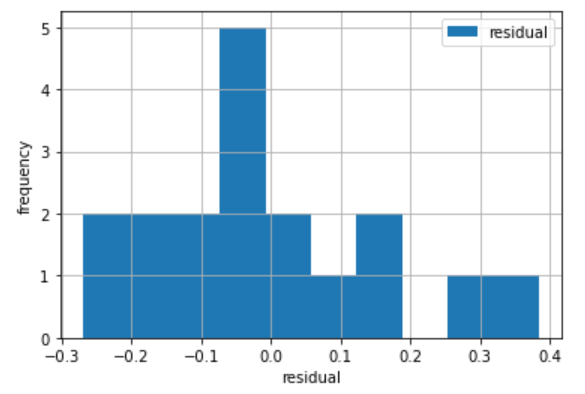
決定係数は0.94とすべての分析期間から大きく改善しました。
またAIC、BIC、JBともに改善していることもわかります。
回帰係数のp値もすべて5%以下に収まっています。
バブル崩壊後
# バブル崩壊後
x_after_bubble = x['1990/1/1':]
y_after_bubble = ln225['1990/1/1':]
model = sm.OLS(y_after_bubble, x_after_bubble)
result = model.fit()
print(result.summary())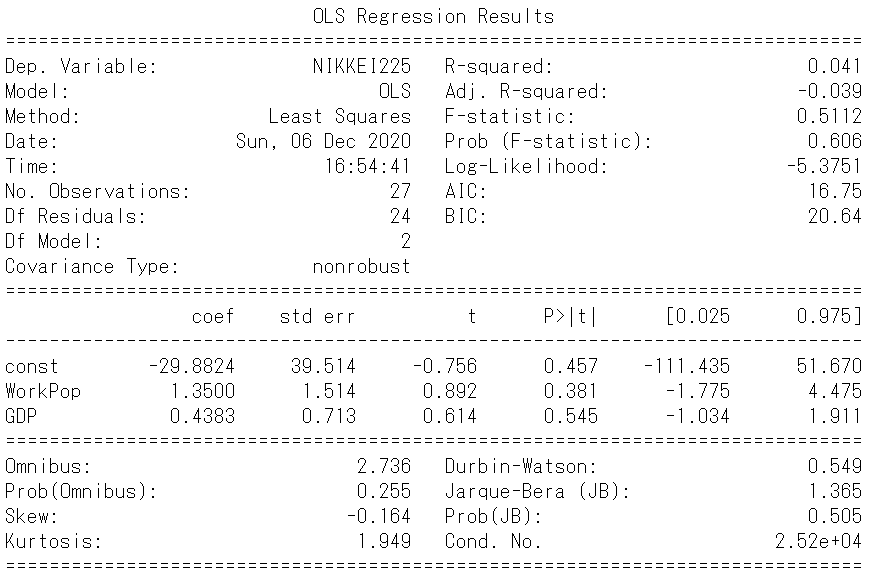
\(R^2\)、AIC、BICともに悪化しています。
回帰係数のp値はすべて30%以上です。
これはどの説明変数も被説明変数の動きをとらえていない可能性を示唆しています。
以上から、バブル崩壊前後で経済が大きく変化する可能性があることがわかりました。
そこで説明変数にドル円の為替レートを追加してみます。
# ドル円を追加
x = pd.concat([x, fx], axis=1).dropna()
# バブル崩壊後 + ドル円
x_after_bubble_fx = x['1990/1/1':]
y_after_bubble = ln225['1990/1/1':]
model = sm.OLS(y_after_bubble, x_after_bubble_fx)
result = model.fit()
print(result.summary())
# グラフを書く
f, ax = plt.subplots() # 2軸グラフ
# 1軸目
ax.plot(y_after_bubble, label='N225')
result.fittedvalues.plot(label='fitted', style='x', ax=ax)
ax.plot(x_after_bubble['GDP']-24, label='GDP', linestyle='--') # 調整
ax.set_ylabel('log Nikkei225 Index')
ax.legend(loc='lower right')
# 2軸目
ax2 = ax.twinx()
ax2.plot(x_after_bubble['WorkPop'], label='WorkPop', linestyle=':')
ax2.legend(loc='upper left')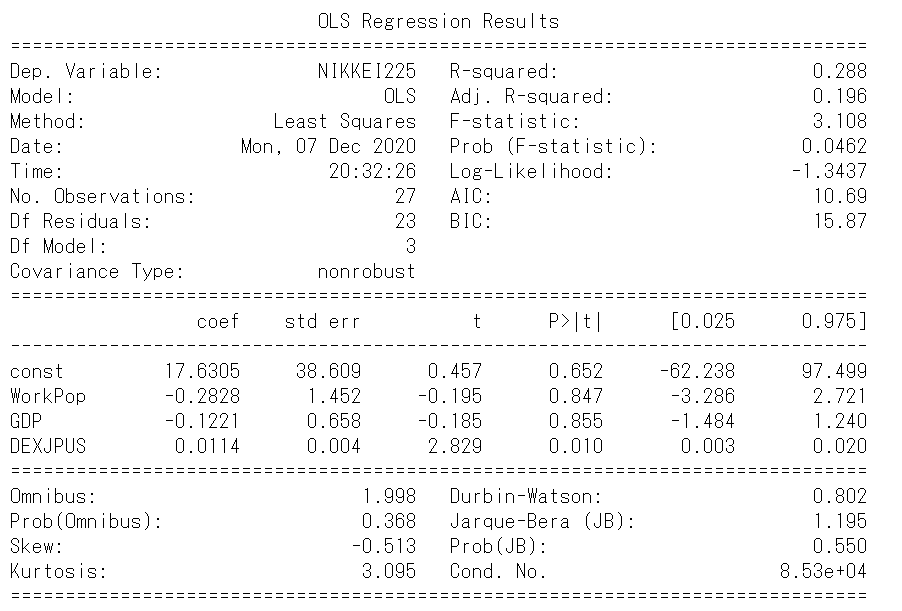
回帰係数のp値について着目してみると、切片、労働人口、国内総生産は大幅に上昇し、ドル円の為替レートは5%以下に収まっています。
決定係数、AIC、BIC、JBは前のモデルより改善しています。
グラフからはリーマンショック以降の期待値は実際の動きをよく説明できているように思われます。
バブル崩壊後の期間を分割
バブル崩壊後の経済についてより詳しく見てみみます。
期間は、以下のように分けます。
- 1990/1/1 ~ 2000/1/1
- 2000/1/1 ~ 2008/1/1
- 2008/1/1 ~ 2016/8/31
import statsmodels.stats.api as sms
sms.jarque_bera(result.resid)
terms = ['1990/1/1', '2000/1/1', '2008/1/1', end]
columns = [] # 表の列名作成用
R2 = []
AIC = []
BIC = []
p_values = []
JB = []
for t, term in enumerate(terms[:-1]) :
columns.append(terms[t]+ '~' + terms[t+1])
x_t = x[terms[t]:terms[t+1]]
y_t = ln225[terms[t]:terms[t+1]]
model = sm.OLS(y_t, x_t)
result = model.fit()
R2.append(result.rsquared)
AIC.append(result.aic)
BIC.append(result.bic)
p_values.append(result.pvalues.values)
JB.append(sms.jarque_bera(result.resid)[1])
# dfにまとめる
df_0 = pd.DataFrame([R2, AIC, BIC, JB], index=["R2", "AIC", "BIC", "JB"])
df_1 = pd.DataFrame(p_values).T
df_1.index = ['切片', '労働人口', '国内総生産', 'ドル円']
df = pd.concat([df_0, df_1])
df.columns = columns
pd.options.display.float_format = '{:.2f}'.format # 桁数を調整
df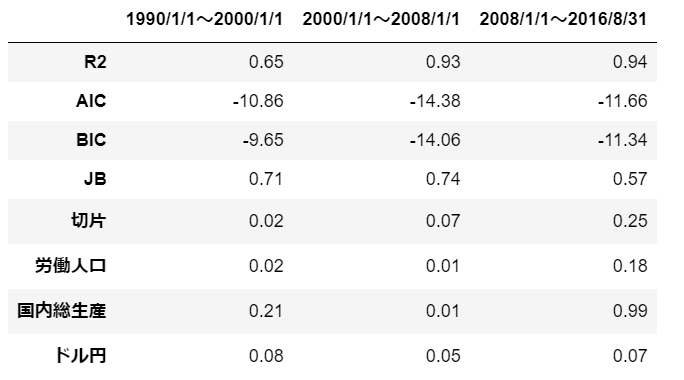
上表から各期間で説明変数のp値が大きく異なり被説明変数に与える影響が異なることがわかります。
1990年~2000年では、労働人口とドル円が日経平均株価の有力な説明変数となっています。
2000年~2008年では、国内総生産がそれらに加わっています。
2008年~2016年では、為替レートだけが有力な説明変数となりました。
つまり、期間ごとに適切な説明変数を選択していく必要があるように思われます。
まとめ
今回は、日経平均株価とマクロ変数との関係について分析してみました。
分析を通して、期間ごとで有効なマクロ変数があることがあることがわかりました。
マクロ変数を追加することで、モデルを改善できることもわかりました。ただし、今回使用したマクロ変数は3個程度なので、他のマクロ変数を加えてより詳細に分析をしてみるなど、色々試す余地は残っています。
分析手法としては、簡単な残差分析と多変量解析を行いました。
残差の分析では、Jarque-Bara検定を用いました。
多変量解析では、OLSにより説明位変数の有効性確認や統計量からモデルの良さを判定しました。
また、グラフを描くことでモデルの予測値(期待値)や残差を目視で確認しました。
ここまでの内容で最低限の時系列分析はできるようになると思います。
次回はこの辺の知識を生かして簡単な売買ルールの作成を行ってみます。

コメント