SIGNATEの日本証券取引所(JPX)主催のコンペ(詳細はこちら)に参加してみました。
今回の記事では、モデルを投稿に至るまでの探索的データ解析(EDA)や実際に作成したモデルについてまとめます。
なお、締め切り1週間前から参戦した為、モデルを投稿することが目的になってしまいました。
特徴量やモデルについて十分な考察ができなかった点は反省する必要があると感じております。
また、チュートリアルを参考にしたため、似通った内容が多々あります。
データについて
以下のデータを使用しました。
- stock_list:各銘柄の情報が記録されたデータ
- stock_price:各銘柄の株価情報(始値・高値・安値・終値等)が記録されたデータ
- stock_fin:各銘柄のファンダメンタル情報(決算数値データや配当データ等)が記録されたデータ
- stock_labels:本コンペティションで学習に用いるラベル(目的変数)が記録されたデータ
stock_list
stock_listは3,711銘柄あり、各銘柄の証券コードやセクター情報などアイデンティティ情報がまとめてありました。
今回のコンペでは、以下に掲げる条件を満たす銘柄を予想対象としており、それに該当するかのフラグ情報も含まれておりました。
- 2020年12月末日時点で、東京証券取引所に上場していること
- 普通株式であること(種類株ではないこと)
- ETF、ETN、REIT、優先出資証券、インフラファンド、外国株のいずれにも該当しないこと
- 2020年12月末日時点で、上場後2年を経過していること
今回は、prediction_targetによるデータの選別を行っておりません。
データは2016年からあったのですが、過去のデータに2020年12月末時点の情報を利用してよいのか疑問に思ったためです。ただ、後日、運営に質問してみたら特に問題ないそうでした。
おそらく、特定の銘柄について予測するモデルを構築する場合はこのアプローチは問題ないと思います。しかし、各時点における市場全体を分析する場合は、このデータを利用するのはアウト(リーク)だと思われます。
例えば、東京証券取引所に上場後2年を経過している銘柄を分析する場合は、各時点でこの条件を満たす銘柄でユニバースを構築する必要があります。
予測対象フラグで絞り込んだ銘柄の特徴を分析をした場合は、条件1~4を満たす銘柄群の特徴分析に過ぎないです。今回のコンペで上位のモデルを構築することが目的であれば予測対象フラグで銘柄を絞り込んで分析・モデル構築をするのが良いと思われます。
また、stock_listには2020年12月30日時点の発行済み株式数の情報があります。
発行済み株式数を用いて過去の株価から各時点の時価総額を算出することはリークとなるので注意が必要です。
時価総額を利用したい場合は各時点の発行済み株式数が必要ですが、今回のコンペのデータには含まれていなかったので、利用することはできませんでした。
stock_listの情報だと、セクター情報や業種別コードが利用できそうに思えます。
これらの情報を用いて銘柄をグルーピングし、各グループで基準化・モデルを構築すると予測精度が高いモデルができるのかもしれません。
実際、金融市場では業種間で特徴がかなり異なるのでこのアプローチはかなり有効な気がします。
今回は時間の関係上できませんでしたが、余裕があるときにでもトライしてみたいと思います。
stock_price
株価の始値・高値・安値・終値などが格納されております。
欠損値について調べましたが、価格情報には欠損値は含まれておりませんでした。
それ以外については特に利用しないため、確認しませんでした。
stock_fin
各銘柄の決算情報(財務データ等)が格納されております。
データ数は81,797ありました。
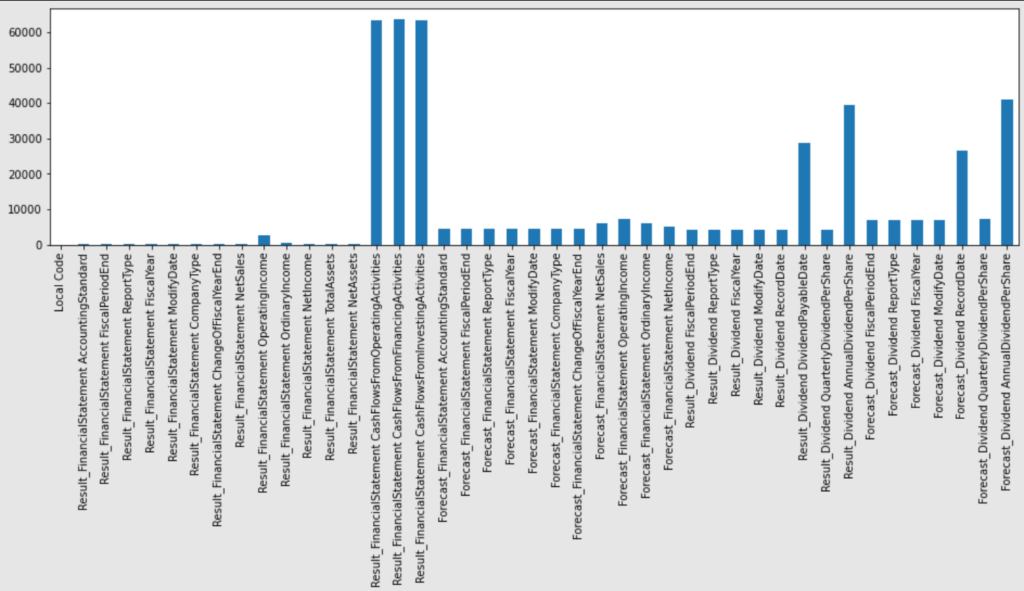
欠損値の分布をまとめたものは以下の通りです。
キャッシュフローや配当に関するデータに欠損値が多く含まれていることがわかります。
チュートリアルを参考に欠損値の推移をプロットした図が以下の通りです。
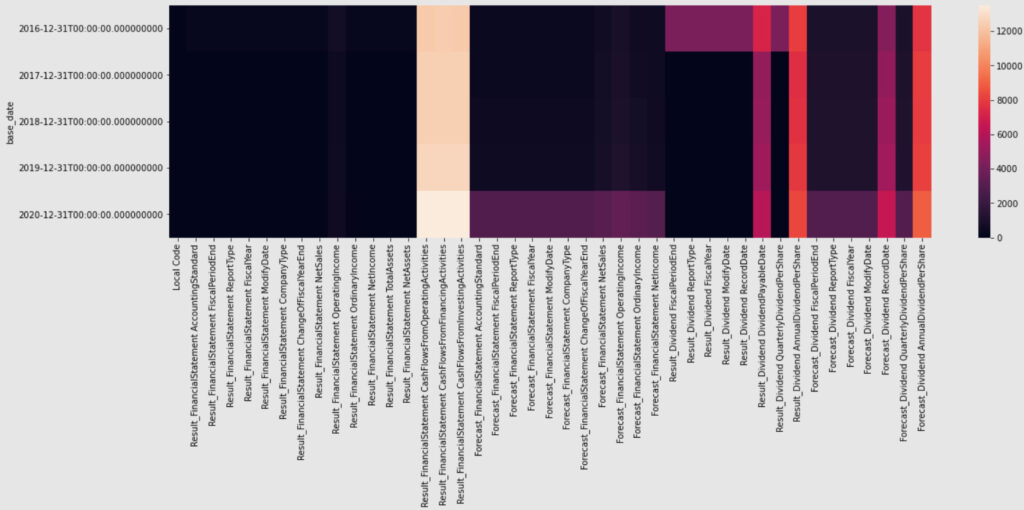
キャッシュフローに関しては時点間関係なくまばらに欠損値があることがわかります。
そのとなりの列の来期予測(Forcast)関係は直近のデータに欠損値が多く含まれております。
2020年から来期予想が欠損値となっているのは、昨今のコロナによる先行きが不透明のため各企業は来期予想を公表していないのかもしれません。
年間当たりの配当は時点関係なく欠損値を多く含んでおりますが、四半期配当金は最初の期間(2016年)を除き、欠損値が少ないことがわかります。
したがって、配当に関するデータは四半期ベースのものを採用します。
stock_label
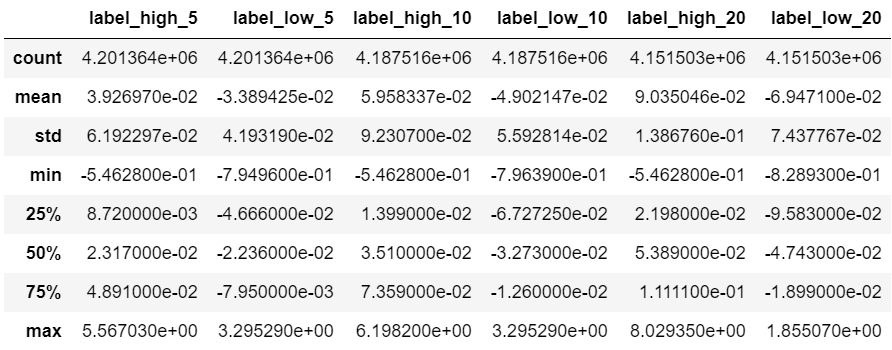
目的変数となる(ラベル)データが格納されております。
各銘柄で決算発表が行われた日の取引所公式終値から、その日の翌営業日以降N(5,10,20)営業日間における最高値及び最安値への変化率を記録したデータとなっております。
データの統計量を算出した表が以下の通り。
上図の統計量の推移をプロットしてみたものが以下の通り。
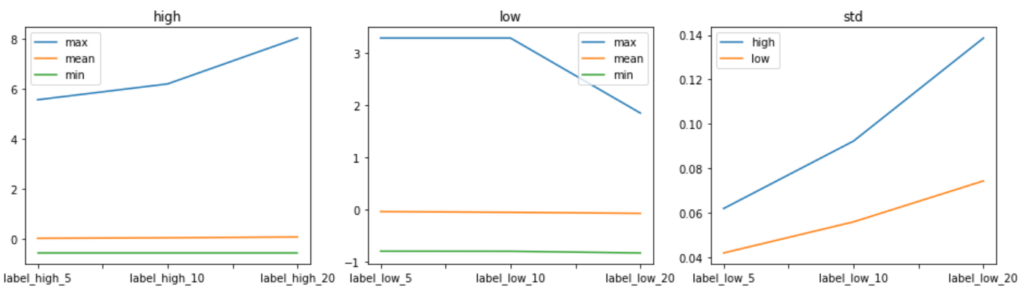
最大値の推移(左図:high)と標準偏差の推移(右図:std)について見ると、最小値・平均値は一定※ですが、最大値は予測期間が長くなると大きくなるのが読み取れます。
それに伴い、標準偏差も増加していることがわかります。
※最大値のグラフにつられて最小値・平均値のグラフが平滑化されてしまっている可能性があります。(本来は、グラフを切り離して分析すべきだったのかもしれません。)
次に、最小値の推移(中央図:low)と標準偏差の推移(右図:std)について見てみると、平均値・最小値は一定ですが、最大値は予測期間が長くなると小さくなっていることがわかります。
それに伴い、標準偏差も増加しています。
最小値が期間を通して一定なのは、下落の場合は急落することが多く、短い期間で価格に織り込まれているためだと思われます。
当たり前かもしれませんが、上昇の場合は価格は徐々に上昇し、下落の場合は価格は急落しその後はその価格帯を推移する特徴が見られました。
各期間幅におけるリターンの分布を図示してみたものが以下です。
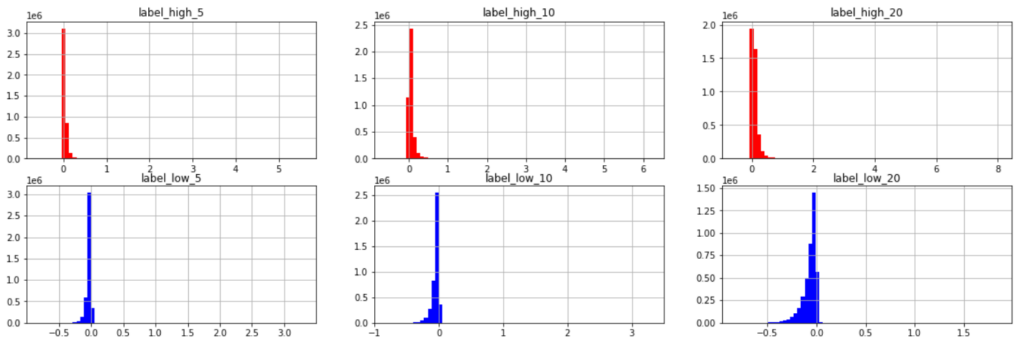
\(x\)軸のスケールを見ると、外れ値のような値を含むことがわかります。
外れ値を丸め込むor除外することも検討してみましたが、今回の予測対象は最大値・最小値であるためそのままの値で残すことにしてみました。
今回の予測対象は、上述の通り、20日間の最高値・最安値です。
予測モデルを構築する際は、それぞれの値をそのまま予測するのが一般的なアプローチだと思われます。
一方で別のアプローチとして、20日後の最高値・最安値の変化率の中間値とその幅(差分)を予測し、最高値・最安値の予測値を算出する方法もあるのではないかと思い、今回試してみました。
差分(high-low)と中間値の分布は以下の通り。
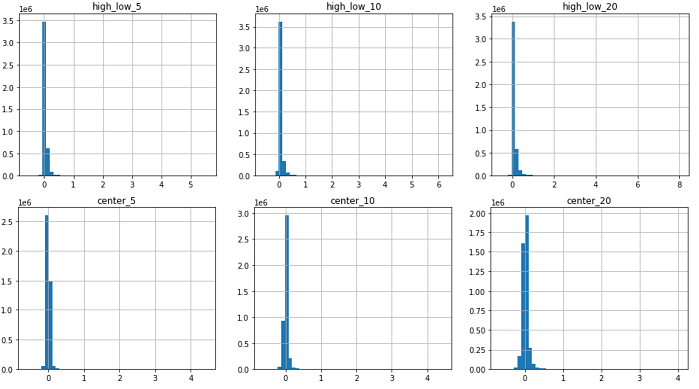
中間値をとると、期間が伸びても最大で4程度で収まるようになりました(予測のブレが減るのか?)。
ここまでをまとめて、今回作成するモデルは以下としました。
- 最高値・最安値を予測するモデル
- 中間値・幅(最高値ー最安値)を予測し、それらを用いて最高値・最安値を算出するモデル
- 1と2を合わせたモデル(アンサンブル・ブレンド):予測値の平均をとる
特徴量(説明変数)の生成
今回のコンペでは、独自でゼロからモデルに入力する特徴量を作成する必要があります。
まず初めに作成していた特徴量は以下の通りです。
尚、チュートリアルに記載があった通り、価格情報などをそのまま利用すると銘柄間でスケールが異なるため、基本的には率変換したものを利用しました。
【テクニカル指標】
- 移動平均乖離率(5日、25日、75日)
- ヒストリカルボラティリティ(5日、25日、75日)
- 過去n日間の最高値(最安値)に対する終値・高値(安値)との乖離率(n=5, 10, 20)
- キリ番との乖離率
- RSI
予測対象が最大値と最小値であるため、高値と安値に対する特徴量があったほうが良いと思い、3つ目を追加してみました。
実際、過去の株価の高値や安値をサポートラインとすることが多いです。
また、キリが良い番号(キリ番)はサポートラインになることが多い為、4つ目の指標を追加してみました。ただ、株価によって見られる価格帯が異なると思ったので、9,999円未満の株価は100円台を基準、 10,000円は1000円台を基準としてみました。そうすることで、銘柄間のスケールもある程度統一されるものと考えました。
【ファンダメンタル指標】
- 売上高営業利益率, 売上高経常利益率, 売上高当期純利益率
- 前期比(成長率)
- 来期予想成長率
- 自己資本比率
- ROE(当期純利益÷自己資本)
- ROA
- キャッシュフローの正負
- 配当利回り
PER, PBRを追加してみたかったのですが、用意されたデータセットの発行済み株式数は未来情報に該当するため、今回は採用しませんでした。
前期比は前年度に公表された同一決算レポートと比較しております。
営業・財務・投資キャッシュフローは、プラスかマイナスかがよく注目されるため、バイナリデータに変換することにしました。
配当利回りは、上述で説明した通り欠損値が少ない一株当たりの四半期配当金を利用しました。
また、修正開示が20日以内の場合は修正前のデータを削除するようにしました。
本来は20営業日にすべきところですが、SIGNATEでの実行環境で営業日ベースの処理が問題なく動作するか不安だったのと簡単のため、日数ベースにしてしまいました。
説明変数間の分析
以下の図は、説明変数間の相関係数をヒートマップに表したものです。
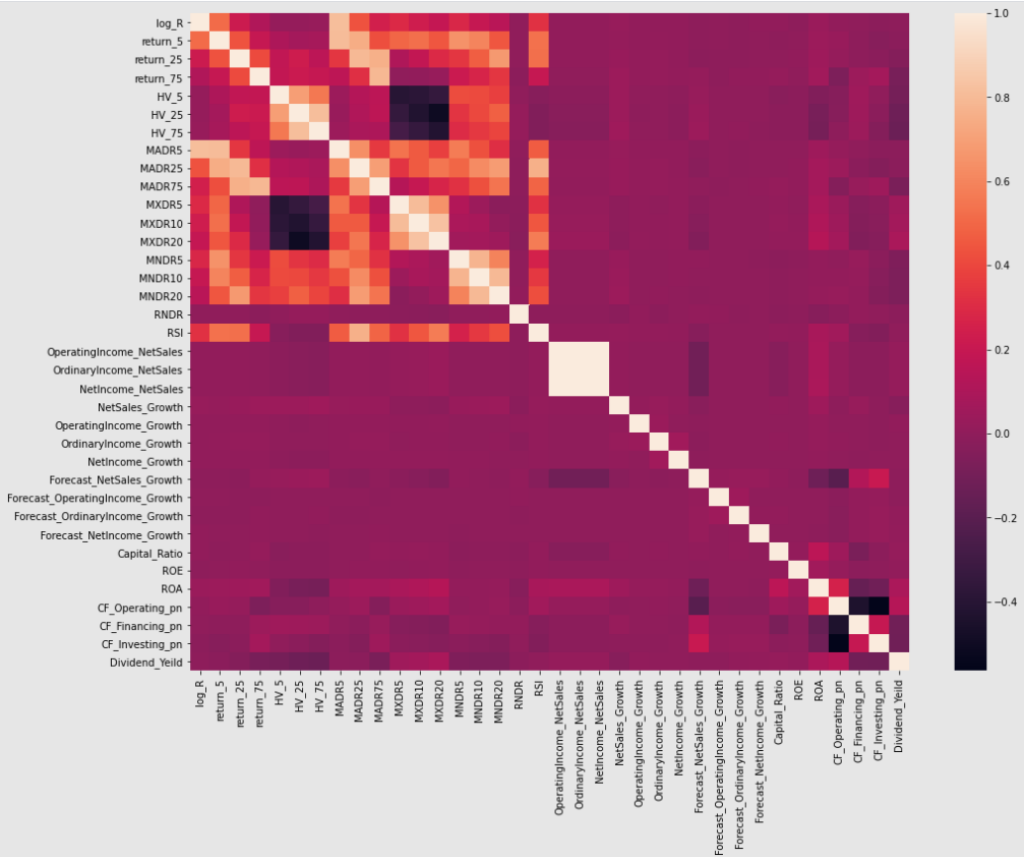
期間が異なるだけの指数同士(例えば、HV5とHV25)は相関が高いことがわかります。
回帰分析のような場合は、多重共線性の可能性を考慮し、相関が高いものについては絞り込みを行ったり、説明変数を生成するなど手を加える必要があります。ただ、今回は機械学習モデルを利用するので特に気にせず、このままモデルの入力に利用したいと思います。
他には、HV(ヒストリカルボラティリティ)が相関が高い傾向があります。
例えば、HVが高くなるとMXDR(過去n日間の最高値との乖離率)が低くなることがわかります。
一方で、MNDR(過去n日間の最安値との乖離率)は高くなります。
HVはどちらかというと価格上方方向と相関が高いように見えます。
説明変数と目的変数の分析
以下の図は、目的変数を横軸に各説明変数の相関をヒートマップにしてみたものです。
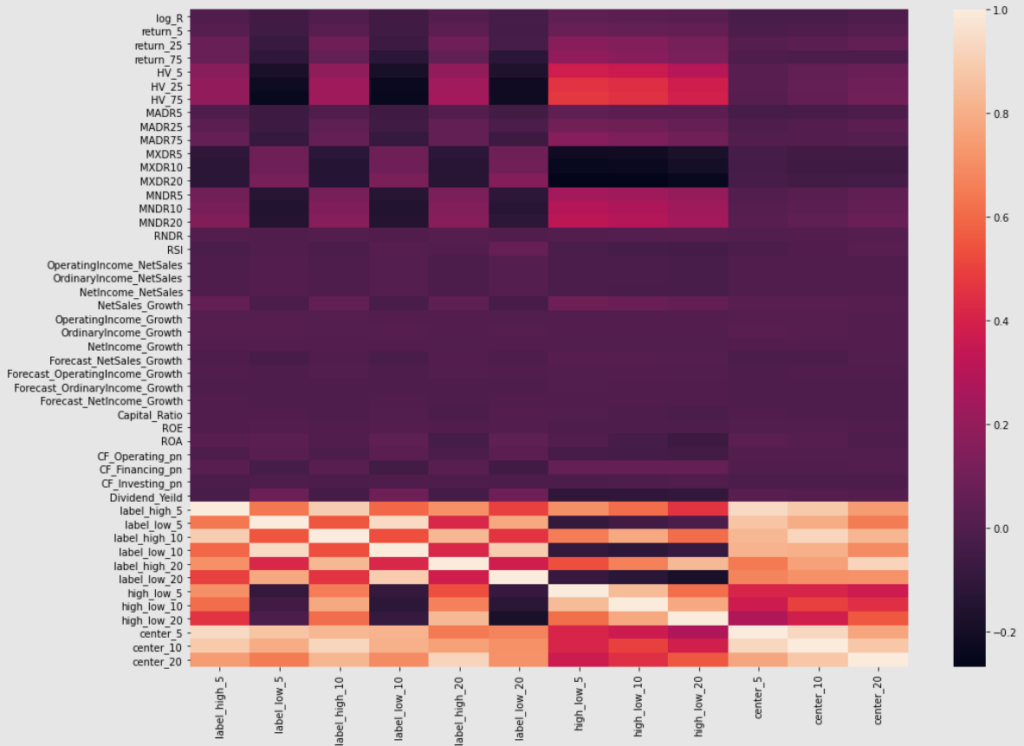
上図から以下が読み取れます。
- HVは最高値・最安値に関するラベルデータに対して相関が見られる。各変化率の差分に関しては、かなり相関がある。
- 移動平均乖離率(MADR)は期間が短いほうがラベルとの相関が高い
- 過去n日間の最高値との乖離(MXDR)と最高値や差分のラベル(n=5, 10, 20)との間に負の負の相関がある(-0.2程度)。最安値との乖離率(MNDR)は、逆方向に同様のことがいえる。
- ファンダメンタル指標はテクニカル指標に比べ全体的に相関関係が低い。
キャッシュフローや配当利回りは相関が高い。 - 期間の異なるラベルデータ同士はかなり相関がある。
以上の結果からHV(ボラティリティ)は重要な変数になりそうです。
また、テクニカル指標の方がファンダメンタル指標に比べ、ラベルデータを捉えるファクターとなりそうな印象です。
今回のような短期的な価格変化予測(20営業日)ではテクニカル指標が重要になり、長期的な価格変化になるにつれ、ファンダメンタル指標の説明力が増していくのかもしれません。
また、配当利回りが思いのほか、ラベルデータとかなり相関があったので重要なファクターになりそうです。
ここまでの結果から、ボラティリティに関係しそうな説明変数を追加して同様の分析をしました。
追加した説明変数は以下の通りです。
- 株価に対する1日当たりの値幅
- (高値-安値) / 終値の20日間移動平均
- 各HVの20日間移動平均
- 出来高
また、セクター間の特徴や季節性を考慮して以下のファンダメンタルデータも追加しました。
以下のデータに関しては、one-hotベクトル化(タミー変数)したものを利用します。
- セクター情報
- 決算レポートの種別
結果は以下の通りです。
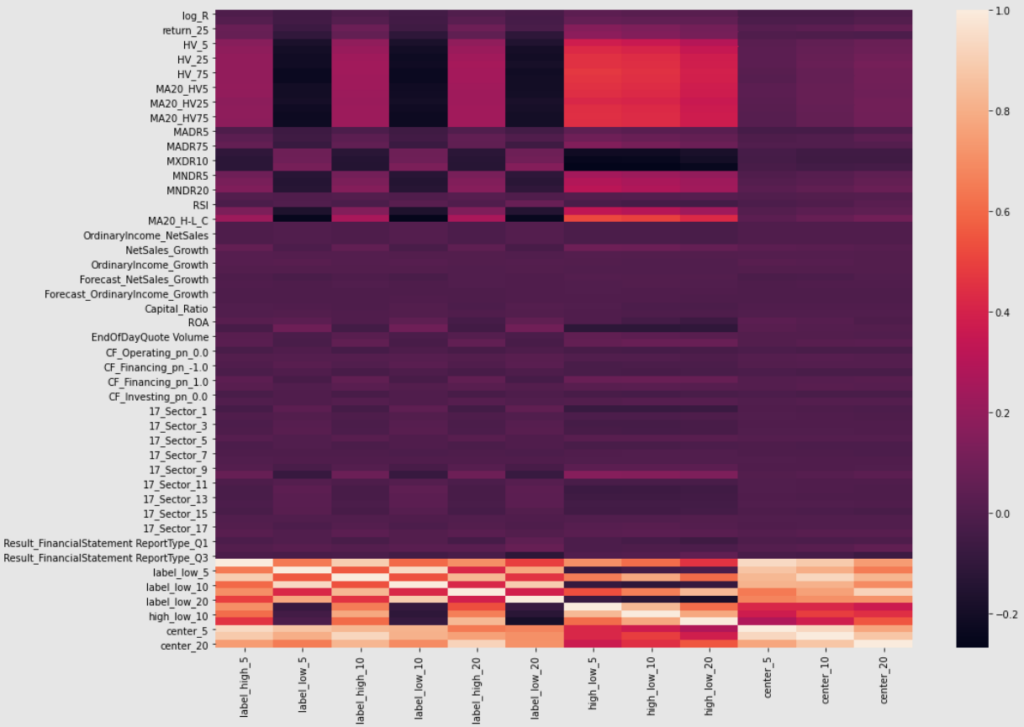
追加した説明変数について以下の内容が読み取れました。
- ボラティリティの平均(MA20_HV)も相関がある
- 値幅(高値ー安値)は相関がある
- セクター情報も相関がみられる
- 決算種別も相関がみられる
モデル構築
上で紹介した特徴量を利用して予測モデルを構築しました。
データの分割はチュートリアルを参考にしつつ、評価期間を1年間としたかったので以下としました。
なお、各データは訓練データのパラメータをもとに標準化処理をしました。
- 訓練期間 :2016-01-01 – 2017-11-30
- 評価期間 :2018-01-01 – 2018-12-01
- テスト期間:2019-01-01 – 2020-12-31
機械学習モデルの選定
試した機械学習モデルは、以下の通りです。(パラメータなどはデフォルト値)
- 線形回帰
- リッジ回帰
- 決定木
- バギング
- アダブースト
- ランダムフォレスト
- 勾配ブースト
- LightGBM
- ニューラルネットワーク(隠れ層:128×3)
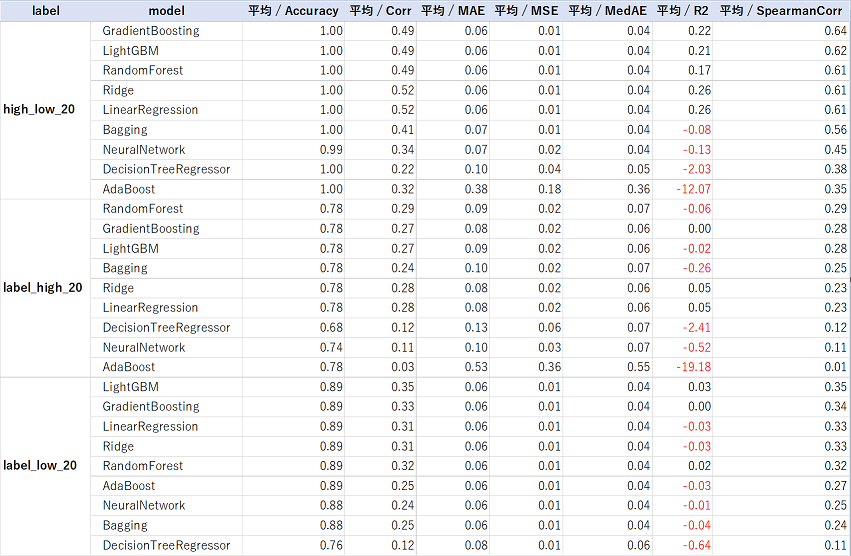
以下の表は、それぞれのモデルのスコアを集計したものです。
【評価データ】
【テーストデータ】
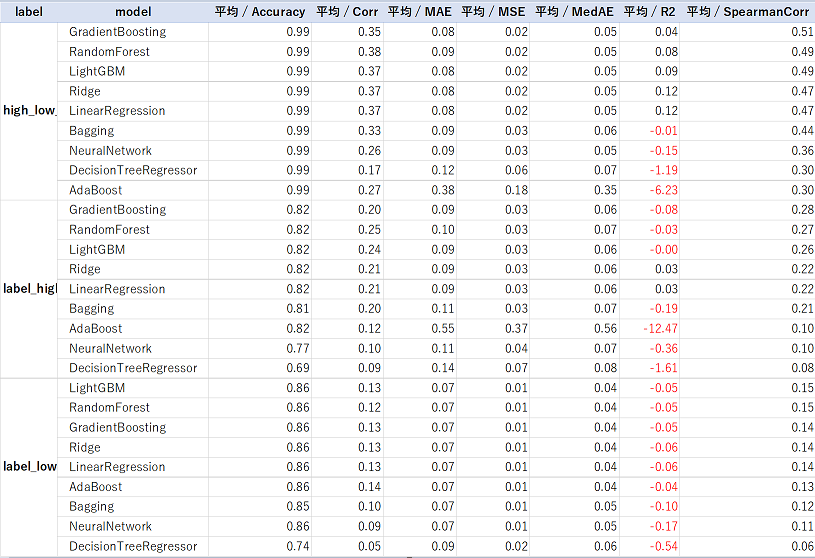
ざっと見なところ、GradientBoostingとRandomForestが良さそうでした。
テスト期間の最安値のスピアマン順位相関係数がかなり悪いように見えます。
コロナショックの影響などを受けているのかもしれません。
今回は時間の都合上、この辺について詳細に見ることができませんでした。
また、モデルのパラメータチューニングも行っておりません。
本来はこの辺に時間をかけるべきだったと反省しております。
ここまでの結果を踏まえ、今回はランダムフォレストと勾配ブースティングの二刀流でコンペに参加することにしてみます。
提出モデルの構築
上で追加した特徴量を含めてモデルを構築しました。
【評価データ】
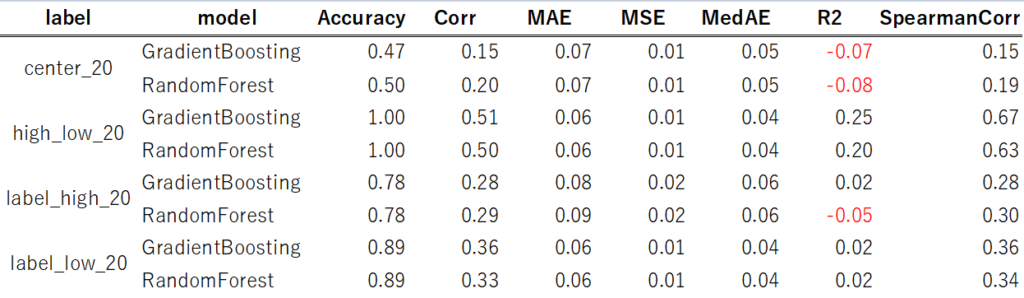
【テストデータ】
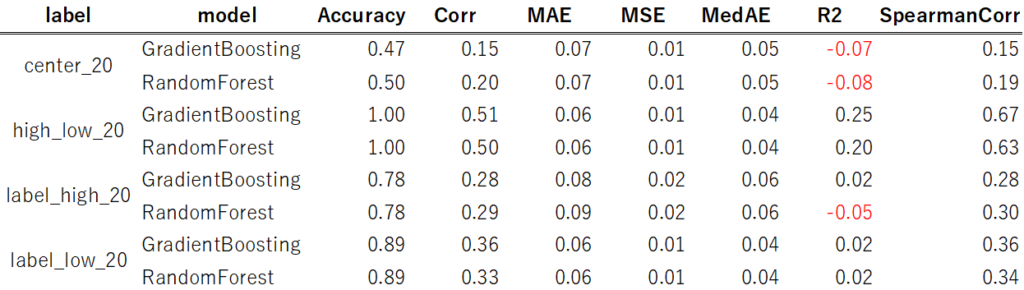
説明変数を追加することでモデルのスコアが改善されました。
説明変数の重要度
次に説明変数の重要度を見てみます。
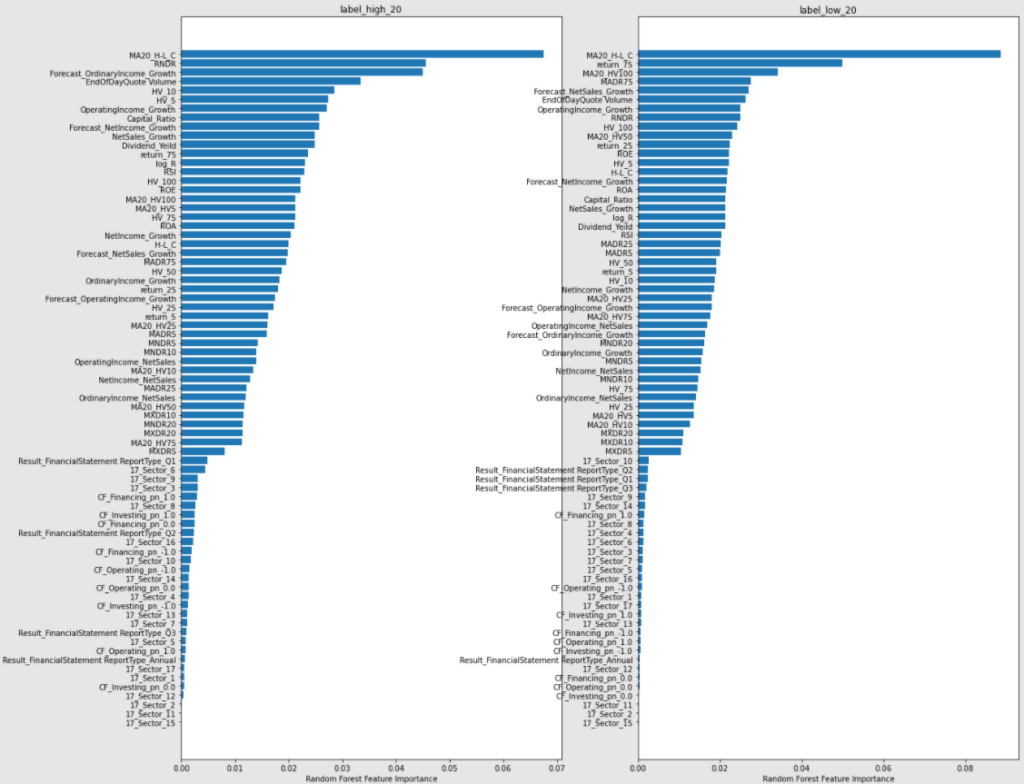
【RandomForest】
【GradientBossting】
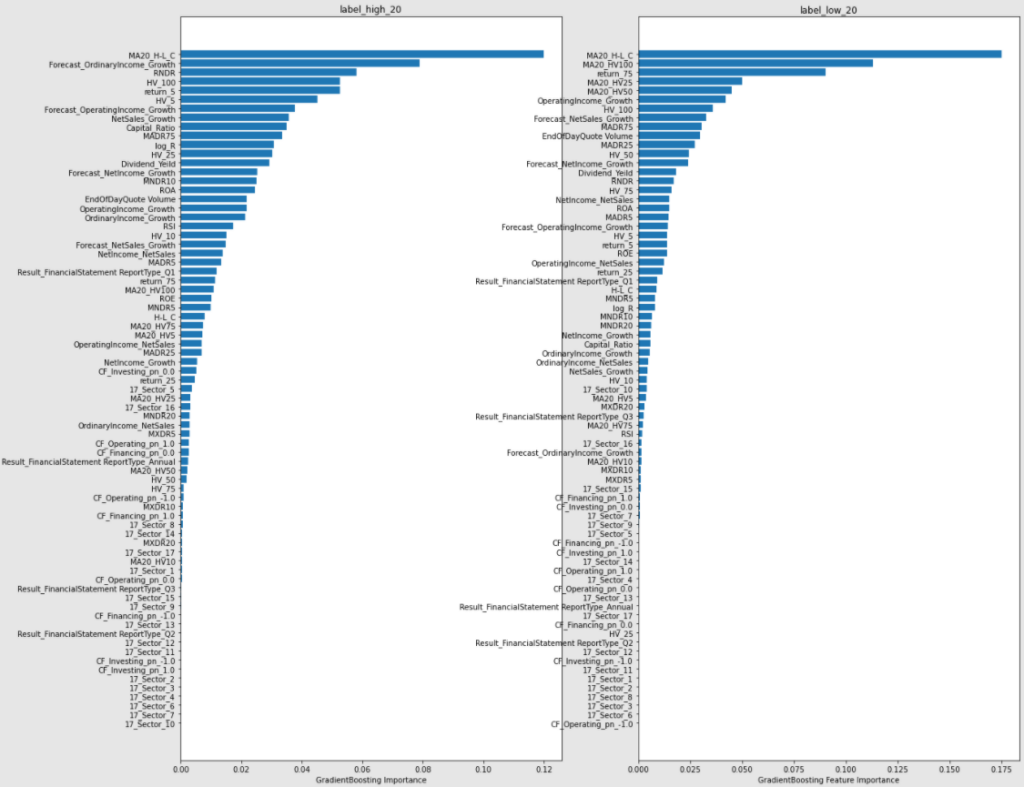
上図を眺めてみてわかったことをざっと以下にまとめておきます。
- 値幅に関する特徴量(H-L_C)がかなり重要であることがわかる
- 出来高(EndOfDayQuote Volume)も重要である
- カテゴリ変数はあまり意味がない
- ボラティリティの重要度がかなり高い
- キリ番(RNDR)が意外と効いている
- 配当利回りも意外と重要
- 来期予測系もかなり効いている
モデルのブレンド(アンサンブル)
上記の各モデルをまとめることでスコアが向上しました。
<補足説明>
- Brend_Center: RFとGBの各中間値ベースモデルのブレンド
- Brend_GBRF: RFとGBの標準モデルのブレンド
- Brend_GB_Center: GBの標準モデルと中間値ベースモデルのブレンド
- Brend_RF_Center: GBの標準モデルと中間値ベースモデルのブレンド
- GB_base_Center: GBの中間値ベースモデル
- RF_base_Center: RFの中間値ベースモデル
- Brend_ALL: RFとGBのそれぞれの標準モデルと中間値ベースモデルの計4モデルのブレンド
※RandomForestをRF、GradientBosstingをGBと省略してます。
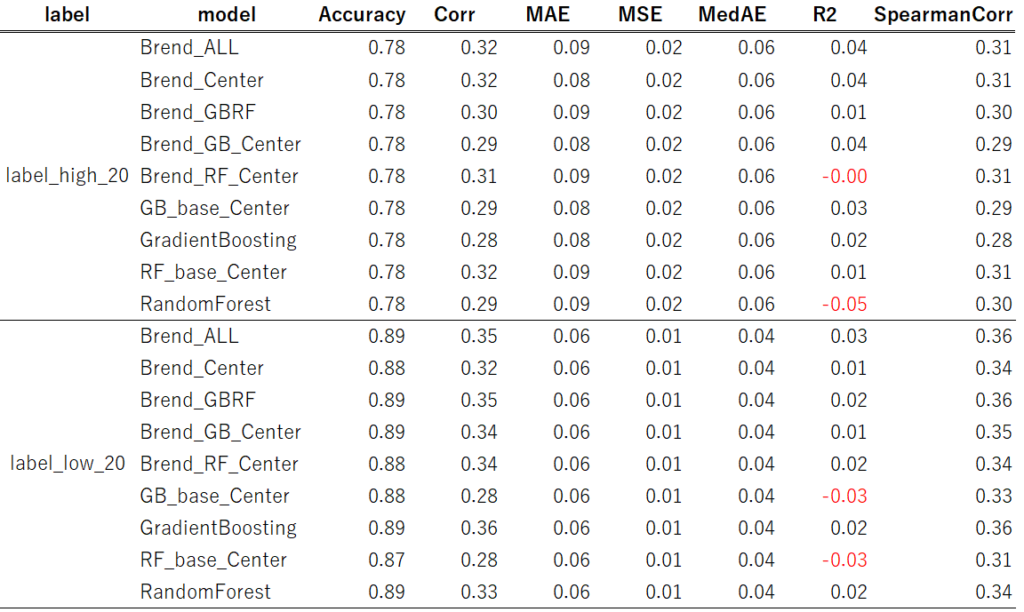
【評価データ】
【テストデータ】
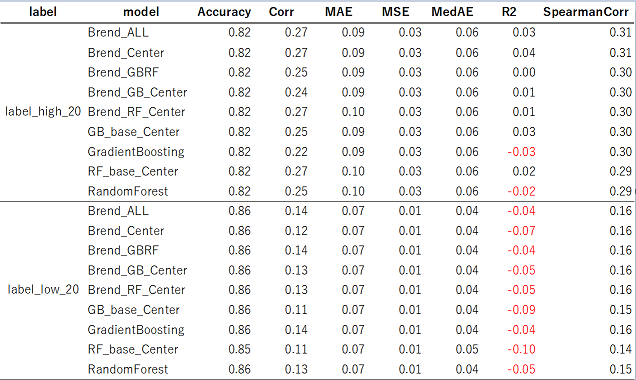
結果として、これらの中でBrend_ALLが安定性(汎化性能)と精度面で良さそうでした。
したがって、Brend_ALLを採用することにしました。
結果
上記のモデルを提出してみた結果、最終評価は”1.4038523”で現時点で211人中95位という悲しい結果でした。
上位に表示される人のうち何名かは2020年のデータを用いたモデル(未来情報をリークしたモデル)を投稿している人と考えると多少順位は上がるかもしれませんが、今回のモデルでは上位は狙えないだろうなと思っております。
学習期間をぎりぎりまで伸ばした(学習データを増やした)モデルではリーダーボードのスコアが若干改善されたものの提出期限に間に合いませんでした…
最終順位はモデル提出締め切り後の市場で評価されるのでまだわかりません。
6月14日に発表される最終順位を楽しみにしたいと思います。
まとめ
今回はSIGNATEの日本証券取引所(JPX)主催のコンペに参加してみました。
締め切り1週間前から参加した割には奮闘できた気がしております。
SIGNATE初心者ということもあり、提出時に手間取りました。
通常はJupter Notebookを用いてまとめて分析しているので、それらをPythonプログラムにまとめて提出先の環境に適合させるのに若干苦労しました。
ただ、これらを通していろいろ学ぶことができてよかったと思ってます。また、チュートリアルも説明が丁寧で金融データ分析について知見を深めることができた気がします。
(おまけ)
今回の記事では機械学習モデルを紹介しましたが、別にディープラーニングモデルも作りました。作成したディープラーニングモデルの結果は散々でしたが、記録がてら次回の記事で紹介します。
ご参考
今回の記事に関するプログラムはGithub(こちら)に公開ております。
【ipynb】
- EDA_public.ipynb: EDAに関するノートブック
- ML_Model_public.ipynb: 機械学習モデルの選定に関するノーブック
- EDA_ML_Model_2_public.ipynb: RandomForestとGradientBosstingに関するノーブック
- ML_Model_public.ipynb: モデルのブレンドに関するノートブック
【src/src_ML】
- predictor.py: 今回のコンペで提出したコード

コメント