前回の記事では、コンペに参加時に行った一連の流れ(探索的データ解析~モデル構築等)についてまとめました。
予測モデルの特徴量には、各銘柄の決算発表日の一時点の価格情報(テクニカル指標)や決算情報(ファンダメンタル情報)を利用しました。機械学習モデルにはRandomForestやGradientBoostingを利用しました。
今回は、各銘柄の決算発表時点のファンダメンタル情報と直近のテクニカル情報の時系列データをインプットにしたディープラーニングモデル(CNNを利用)を構築してみたので記事に残しておきます。
結果は前回のモデルよりも悪化してしまいました。ただ、改善の余地は十分あると思っております。
(コンペの締め切り間際で改善をしている余裕がなかったです…。)
モデル構築の経緯
前回の記事で紹介した機械学習モデルでは、決算発表時のデータ(クロスセクションデータ)しか利用しておりませんでした。
ファンダメンタル情報は時期列データとして利用するのは困難ですが、テクニカル情報を時系列データとして利用することで精度向上の可能があるように思われます。
各銘柄の価格情報がランダムウォーク(確率的トレンド)だとすると、過去の価格やテクニカル指標を利用した将来予測は困難です。
しかし、世の中にはテクニカル分析という価格の形成パターンによる予測から成果を出している猛者がいるのも確かです。
将来の価格(今回の場合だと将来の最高値・最安値)が過去の価格情報・テクニカル情報をもとに形成されているのであれば、それらをモデルにうまく組み入れることができば予測精度は向上するはずです。
本来であれば、各銘柄の価格についてランダムウォークの検定をする等、モデルを構築までに様々なステップを踏まないといけないのかもしれません。
今回は時間の都合上、そこまでの労力を費やすのは困難だったので、試してみてうまくいけばラッキー程度の気持ちで取り組んでみました。
モデルについて
今回のモデルには、1次元畳み込みニューラルネットワーク(1D-CNN)を利用します。
時系列モデルだとまず初めにRNNを思い浮かべるかもしれませんが、学習時間が短くて成果が出ている1D-CNN(正確にはTCN)を採用することにしました。
モデルの学習(エポック数)は、val Loss(評価データの損失値)が一定の値に収束するまでとしました。
実装はGoogle Colaboratoryで利用しましたが、セッションが切れてしまい、モデルの保存・読込みを繰り返すような汚い処理となってしまいました。
先日参加したKagleのコンペで同じようなモデルを作ったので、時間の都合上、それを流用しました。Kaggleで使用したモデルについては以下の記事にまとめてます。
データセット
モデル構築で使用したデータセットについては、前回利用した特徴量と大差ありません。
違いとしては、テクニカル指標は決算日から過去\(n\)日間分の時系列データを入力データとして使用するようにした点だけです。
ここで、\(n\)についてはこちらで設定する必要があります。
今回は\(n\)の探索をしている余裕がなかったので、ひとまず\(n=5\)としました。
\(n=5\)とした理由は、上で紹介したKaggleのコンペでスコアが良かったためです。
また、時系列データの中には、決算発表日から\(n\)日経過してないものも存在したため、前処理でそのようなデータは除外するようにしました。
なお、データセットを扱いやすくするため、PytorchのDatasetクラスを継承しております。
全銘柄の情報を持つとメモリが不足してしまう可能性があります。
そこで、このクラスでは、銘柄(正確にはインデックス番号)が指定されるたびに、対象となる銘柄の時系列データの生成とファンダメンタルデータ・ラベルデータの抽出を行い、データセットとして返すように工夫しました。
入力データ(特徴量)
今回のモデルには、テクニカル指標の時系列データとファンダメンタル指標の2つを入力データとして利用します。
ちなみに時系列データは、5×30(\(n\)×テクニカル指標の数)の形をしております。
ファンダメンタル指標に関するデータは、1×46(ダミー変数を含むファンダメンタル指標の数)のを計上をしております。
詳細については、以下にまとめておきます。
【テクニカル指標】
- 出来高
- 対数リターン
- 変化率(5日、25日、75日)
- 移動平均乖離率(5日、25日、75日)
- ヒストリカルボラティリティ(5日、25日、75日)
- 各HVの20日間移動平均
- 過去n日間の最高値(最安値)に対する終値・高値(安値)との乖離率(n=5, 10, 20)
- キリ番との乖離率
- RSI
- 終値に対する1日当たりの値幅
- (高値-安値) / 終値の25日間移動平均
【ファンダメンタル指標】
- 売上高営業利益率, 売上高経常利益率, 売上高当期純利益率
- 前期比(成長率)
- 来期予想成長率
- 自己資本比率
- ROE(当期純利益÷自己資本)
- ROA
- キャッシュフローの正負※
- 配当利回り
- セクター情報※
- 決算レポートの種別※
※については、ダミー変数化(one-hotベクトル化)して利用しました。
ラベルデータ
前回の機械学習モデルの時と同様に、以下の4つのラベルを使用します。
- 20営業日のうちの最高値
- 20営業日のうちの最安値
- 20営業日の終値の平均値
- 20営業日のうちの最高値と最安値の差分(幅)
モデルの予測では、3点目、4点目の中間値・幅(最高値ー最安値)から最高値・最安値を算出します。
そして、最終的にこれらを平均したものを予測ラベルとして利用します。
モデル構成
ディープラーニングモデルは、TCN(Temporal Convolutional Network)を利用しました。
モデル構成のイメージ図は、以下の通りです。
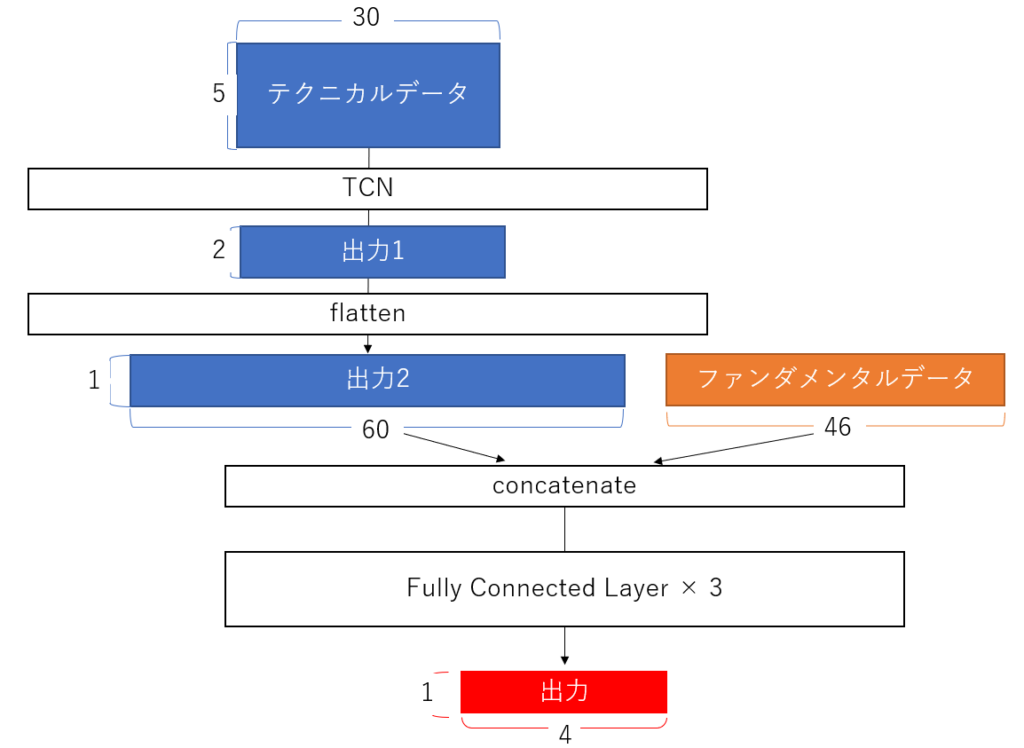
モデルの流れについて簡単に説明します。
まずはじめに時系列データをTCNにより特徴量を集約します。
次に集約された特徴量とファンダメンタルデータを結合します。
そして結合された特徴量を全結合層を通して、予測結果を出力します。
学習の結果
40エポックほどで学習は落ち着きました。
(学習の経過ログをとっておくべきだでしたが、忘れてしまいました。)
参考程度ですが、学習の経過記録を一部以下に記載しておきます。
詳細は、最後に載せるノートブックをご参照いただければと思います。
なお、Google Colaboratoryで学習をし、セッションが切れたりで途中で再学習を繰り返しております。
その為、エポック数の数字が途中から初期化されております。


左の画像が学習序盤で、右の画像は学習終盤の経過を表しております。
学習序盤は、train Lossが5847でval lossが2435とかなり大きな値となっております。
一方で終盤となると、train Lossは460程度で, val lossは170程度とかなり改善されている様子が見られました。
結果
上記のモデルを投稿してみた結果は以下の通りです。
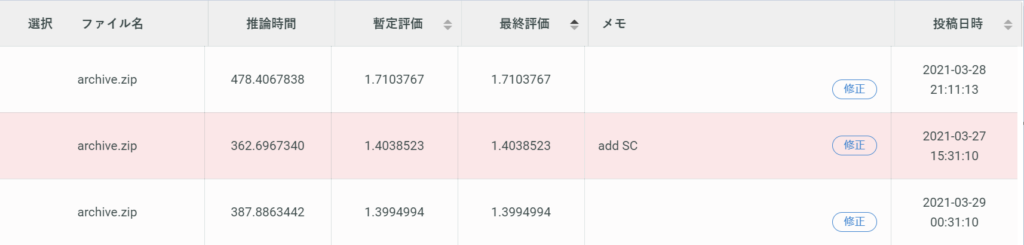
一番上が今回のDLモデルで、下二つが前回の記事で紹介したMLモデルの結果です。
MLモデルよりも評価が低いモデルとなってしまいました。
モデルの予測値の基本統計量と予測値の分布は以下の通りです。
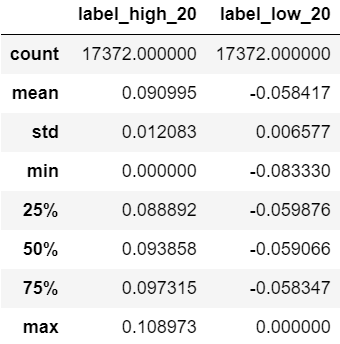
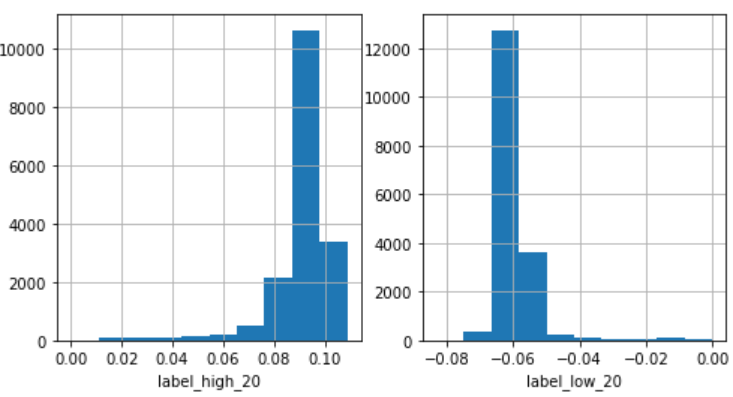
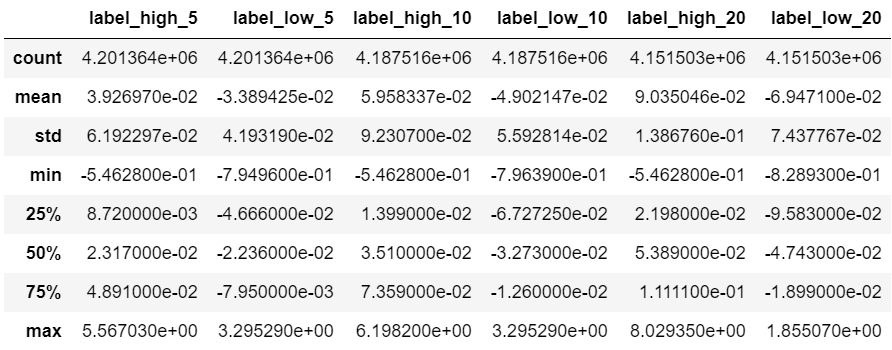
以下の表は、ラベルデータ全体の基本統計量をまとめたものです。(前回の記事から引用)
モデルの最高値に対する予測値は全体的に約0.09付近に偏っていることがわかります。
一方で、ラベルデータ全体の平均は約0.09であるものの、全体のデータの取りうる幅は大きいです。
つまり、ディープラーニングモデルは、ほとんどが平均付近しか出力できないものとなっています。
最安値に対しても同様のことが言えます。
損失関数にはMSE(平均二乗誤差)を利用しましたので、学習で予測が平均に偏ってしまうのもなんとなくイメージが湧きます。平均付近の値を予測値とすることで全体的な損失値は下げることができるためです。
train lossやval lossがある一定値に落ち着いているのは、平均付近を予測したためだと思われます。
以上のように、今回作成したモデルには課題が多くあります。
まとめ
今回は、SIGNATEの日本証券取引所(JPX)主催のコンペで作成したディープラーニングモデルについて簡単に紹介してみました。
結果は良くなかったですが、時系列データ(テクニカルデータ)とある一時点のデータ(ファンダメンタル指標)を組み合わせたモデルを構築できたのは勉強になりました。
金融データは発生頻度が不均一です。日次で得られるものもあれば、年次でしか得られないものもあります。このようなデータを最大限活用するアプローチとしては、今回のようなやり方も考えられるのではないでしょうか。時系列データを圧縮した特徴量とクロスセクションデータをConcatanete(結合)し、その特徴量(ベクトル)をモデルのインプットとして扱うことでモデルを作ることができました。
今回は時間の都合上、モデルの改善をしている余裕がありませんでしたが、時系列データとクロスセクションデータを組み合わせたモデルには改善の余地があるように感じております。
次はニュース分析のコンペに参加してみます。
ご参考
今回の記事に関するプログラムはGithub(こちら)に公開ております。
【ipynb】
- DeepLearningModel_preprocessing_public.ipynb: データセットの作成~モデル構築準備
- DeepLearningModel_Train_public.ipynb: モデルの学習に関するノートブック
- DeepLearningModel_Predict_public.ipynb: モデルの予測に関するノートブック(メモ)
【src/src_DL】
- /model/model.mdl:学習済みの重み
- /src/predictor.py:今回のコンペで提出したコード
コメント