前回の記事では、ニュース記事を業種区分やクラスタリングして分析してみました。
そして投資対象から除外したほうが良いセクターを特定しました。
また、クラスタリングの結果、クラスター間でリターンの差があることがわかり、投資対象とすべきクラスターを特定しました。
今回は上記の結果に基づいたポートフォリオ組成戦略を構築したので、それについて記事にまとめます。
そして最後には、構築したモデルを提出した結果などを記したいと思います。
ポートフォリオ組成戦略
今回考案するポートフォリオ構築の手順は以下の通りです。
- 直近の1週間のニュースを取得し、BERT特徴量に変換
- 1.の特徴量をクラスタリングし、クラスター7の銘柄に絞る
- 業種区分によるスクリーニングをする
- 特別損失銘柄は除外する
- LSTMモデルによりユニバース(投資対象銘柄群)と各業界のセンチメントスコアを算出
※各スコアは学習期間のパラメータ(平均, 標準偏差)に基づき基準化したもの - 5.のユニバースに対するスコアから現金比率を決定する
- 5.の各業種のセンチメントスコアからセクターへの投資比率を決定する
- 直近のニュースであるもの優先的ソートする
LSTMモデルの構築
チュートリアルの6章を参考にモデルを構築していきます。
モデルへのインプットは直近のニュースのBERT特徴量(MAX 1000個)とし、ラベルは週次のユニバースのリターンとTOPIX-17の各業種のリターンの騰落([0 or 1]の18次元のベクトル)とします。
なお、予測値は、sigmoid関数で確率値に変換されます。
チュートリアルの再現
チュートリアルでは、予測対象を投資対象のユニバースの週次リターンとしておりました。
学習データ・テストデータは2020年1月1日~2020年12月31日のニュース情報としていたので、今回はデータ数を2021年3月31日まで増やして再現をしてみたいと思います。
なお、2021年のデータはJ-QuantsAPIから取得したものを利用しました。
手順はチュートリアルとほぼ同じため、説明は割愛します。
まずは、2021年1月1日~3月31日をテスト期間として予測値と実測値の相関を見てみました。
その結果は以下の通りです。
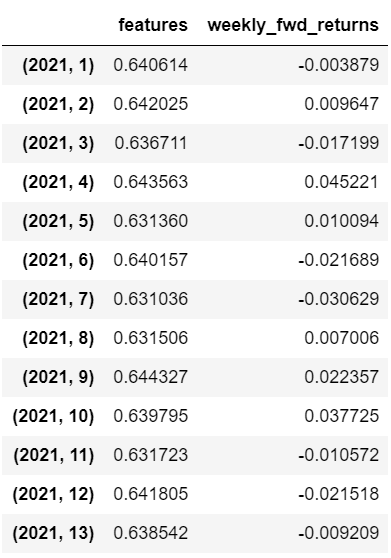
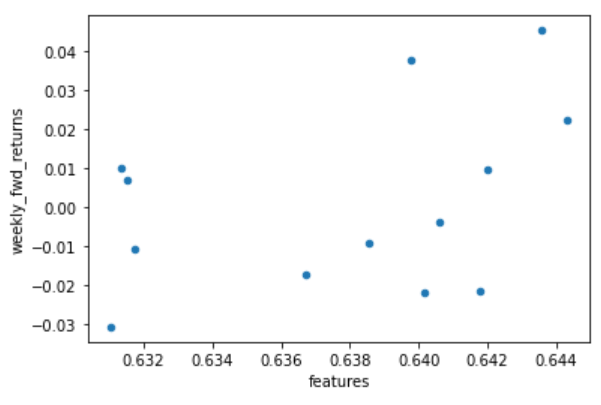
相関係数は0.394とそこそこ高い数値となりました。
テスト期間のサンプル数を増やした場合も同様に高い相関になるか気になったので、次は学習データとテストデータと1:1くらいの割合にしてみました。
テストデータに対する予測値と実際のリターンの散布図は以下のようになりました。
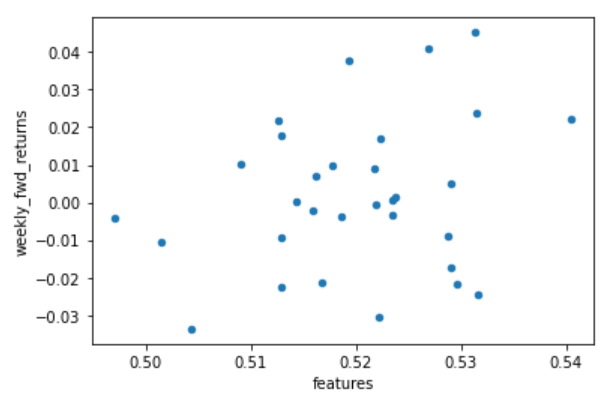
相関係数は、0.253で先ほどの結果に比べると落ちてしまいましたが、相関はややあるように見えます。
チュートリアルにおける相関係数は0.604でしたが、データ量も異なるので概ね再現はできているのではないでしょうか。
ただ、LSTMモデルを学習する際は初期値にかなり依存してるように思えました。
上記の結果は何回か学習させてそこそこよかったものを掲載しております。
場合によっては、負の相関になるようなこともありました…。
複数リターン予測モデルの構築
チュートリアルのモデルを改良します。
改良点としては、出力を18次元のベクトルに変更します。
1次元目はチュートリアルと同様のユニバース全体の週次リターンです。
以降の2~18次元目は、TOPIX-17の各業種に対応する週次リターンです。
Pythonでは0スタートなので、TOPIX-17のセクター番号とカラム番号は整合性が取れるようにしております。
また、インプットには、チュートリアルと同様に直近のニュースのBERT特徴量とします。
ニュースを業種ごとに分類するというような処理は特に行っておりません。
その理由は、ある業種の週次リターンは、他業種のニュースの影響を受ける可能性があると思ったためです。
業種間の関係性について詳細に分析し、インプットについては吟味すべきかもしれません。
しかし、今回は時間もないのでディープラーニングモデルにお任せすることにしました。
プログラムの変更点としては主に以下の通りです。
- 業種ごとの週次リターンを計算 & ラベルを18次元のバイナリベクトルとする
- 1.に伴い、LSTMモデルを変更する
2点目について補足します。
今回のケースは、バイナリのマルチラベル分類問題になります。
ラベルが[0, 1, 0, …, 1]のようになっており、各カラムが1対1で正しいかを評価する必要があります。
そのような場合は、活性化関数にはsoftmax関数を利用するのではなく、sigmoid関数を利用します。また、損失関数には、バイナリクロスエントロピーを利用します。
そうすることで、各カラムに対する予測値を出力できるようになります。
(こちらのサイトを参考にしました)
結果は以下の通りです。
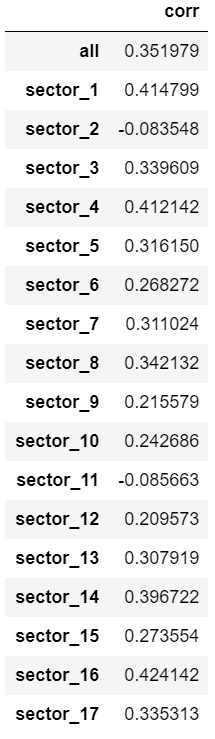
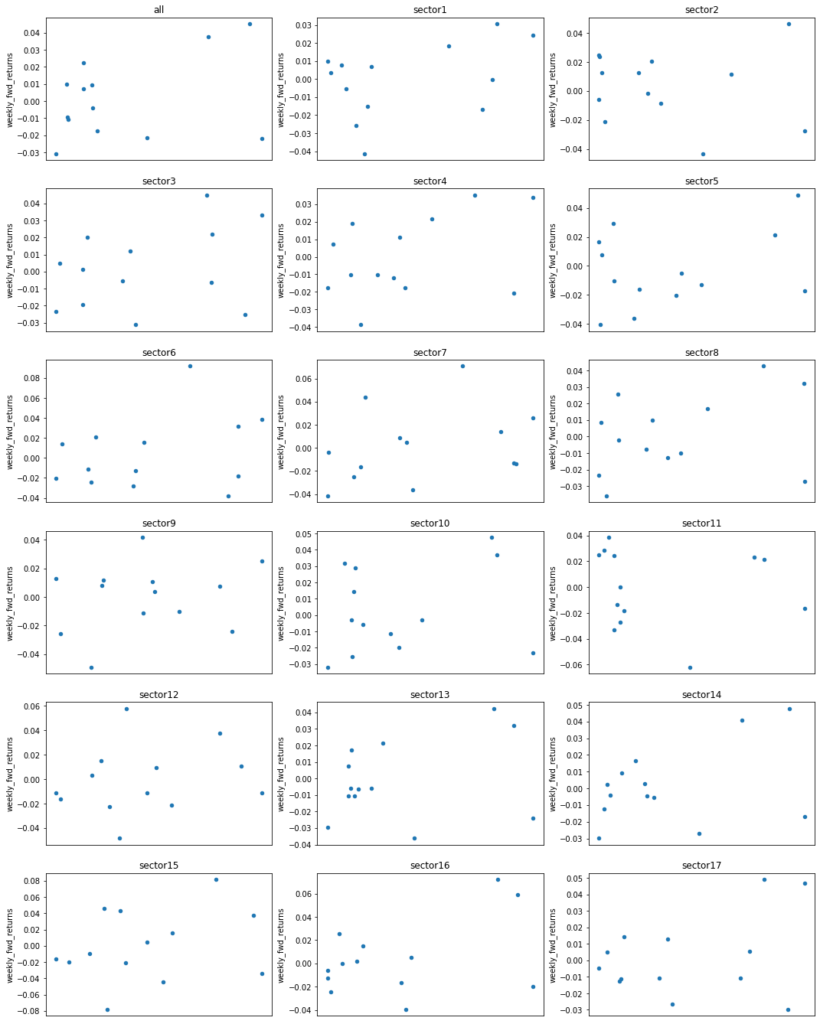
まず、投資対象銘柄全体の週次リターンに対する相関を見てみると、0.35とそこそこ高い数値となっとります。
上での再現に比べると若干劣るものの悪くはないのでしょうか。
次に各業種の相関係数を見てみます。セクター2とセクター11を除き、正の相関があることが確認できます。
今回は、セクター2, 11は投資対象外としているので気にしなくてよいでしょう。
今回は横着をしてモデルの出力を各業種のリターンベクトルとしました。
ユニバースの週次リターンと各業種の週次リターンの予測で全18個のLSTMモデルを構築しないと駄目なものだと思っていましたが、案外、一つのモデルに統合しても機能することがわかりました。
ここまででポートフォリオ組成戦略に必要な材料は揃いました。
以降は、ポートフォリオ組成戦略について詳細に説明します。
1. 直近の1週間のニュースを取得し、BERT特徴量に変換
ニュース記事は公表後、20日前後で価格に織り込まれる様子が見られました。
ポートフォリオ組成が金曜日のマーケットが閉じてからであり、運用期間が翌週の月曜~金曜日ということなので、直近の1週間のニュースを利用するのが良さそうだと考えました。
2. 1.の特徴量をクラスタリングし、クラスター7の銘柄に絞る
BERT特徴量のクラスター間でリターン差が見られました。
その中でもプラスのリターンの傾向があるクラスター7に絞り込みます。
利用したK-meansモデルは、2020年1月1日~2020年12月31日のニュースも利用して構築したものとなっております。
3. 業種区分によるスクリーニングをする
セクター2, 11, 12, 15は、ニュースが株価に負の影響を与える可能性がありました。
また、クラスター7の銘柄からこれらのセクターを除外することでリターンが向上する様子が見られました。
したがって、あらかじめこれらのセクターは除外することにします。
4. 特別損失銘柄は除外する
チュートリアルで紹介されていたものをそのまま利用しました。
ただ、ポートフォリオ組成時の検証では、上記のスクリーニング後の銘柄に特別損失銘柄は含まれていなかったのであまり効果はないのかもしれません。
5. LSTMモデルによりユニバースと各業種のセンチメントスコアを算出
上で紹介したLSTMモデルを利用します。
各スコアは、業種間で比較できるようにするために基準化しておきます。
6. 5.のユニバースに対するスコアから現金比率を決定する
ユニバース(投資対象銘柄群)の週次リターンに対するセンチメントスコアはチュートリアルで紹介されていたように現金比率の調整に利用します。
投資比率は、センチメントスコアに基づき、50%, 60%, 70%, 80%としました。
運用中の1週間で相場が当初想定しない方向になった場合のリスクに備えて、少なくとも20%は手元に残しておくようにしております。
7. 5.の各業種のセンチメントスコアからセクターへの投資比率を決定する
各業種のセンチメントスコア(基準化済み)から各セクターへの投資比率を決定します。
そして、各セクター内におけるスクリーニング後の銘柄へは、均等金額で投資するものとします。
8. 直近のニュースであるもの優先的ソートする
ニュース公表直後の方が株価へのインパクトが大きい為、直近のニュースを優先的に投資するようにしておきました。
バックテストとモデルの提出
バックテストの結果
上記の手順で構築したポートフォリオについて検証してみました。
検証には、本コンペで提供されてるbacktest.pyを利用しました。
検証期間は、2020年の最終2週間だけとなっております。
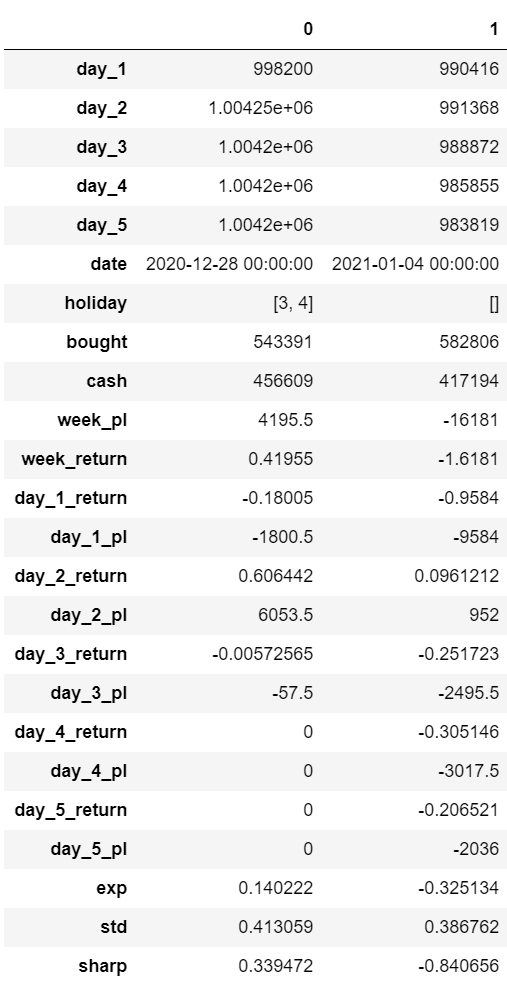

結果を見ると、2020年12月28日のポートフォリオは利益となりましたが、2021年1月4日分のポートフォリオについてマイナスとなってしまいました。
構成銘柄に関する情報は以下の通り。
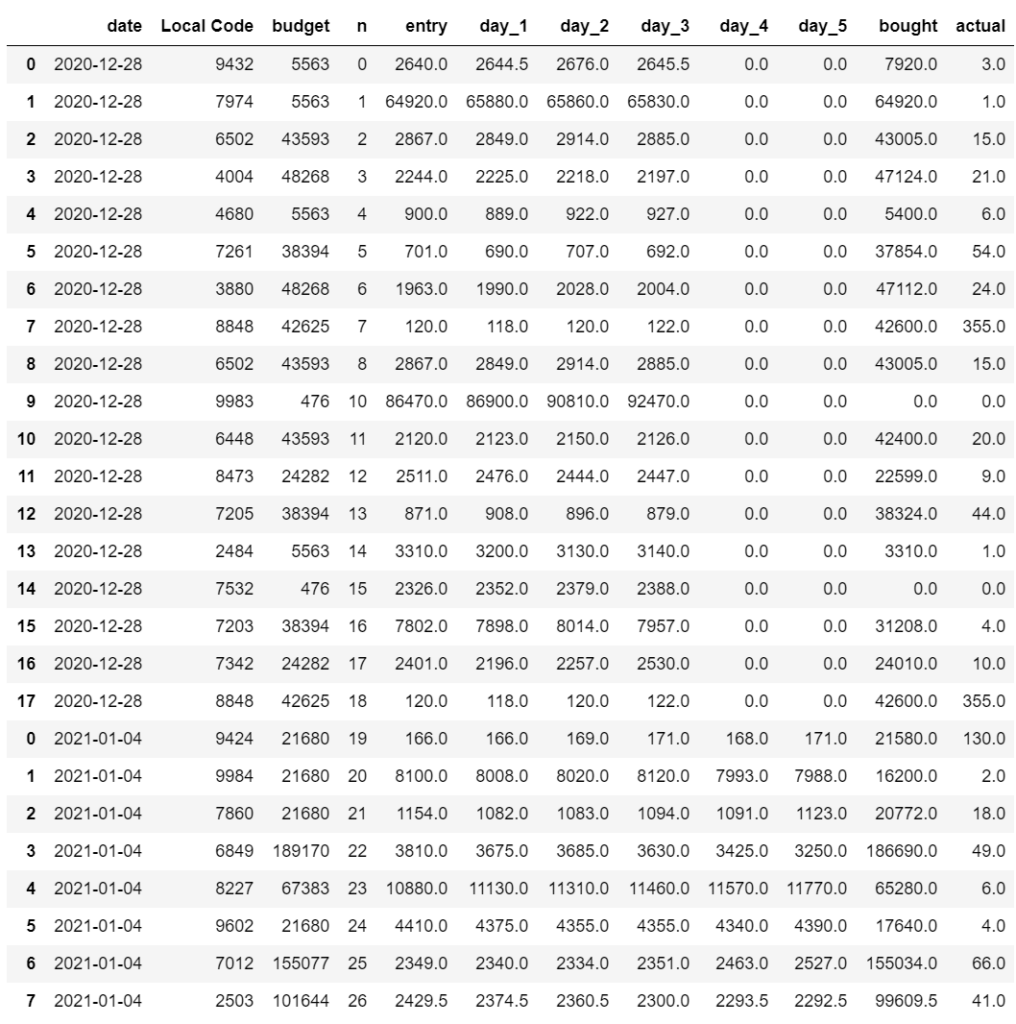
本来は、この辺の検証をじっくりやるべきだと思うのですが、幾分時間がないので諦めます。
ただ、結果を見る限り、問題なく計算はできているようなのでモデルの提出は何とか出来そうです。
モデルの提出
最後にここまでに作成したモデルをSIGNATEに投稿してみました。
リーダボードの結果は、評価が約25701で131人中130位・・・
とりあえず、モデルの提出するという最終目標は達成できたものの結果が悲惨すぎます…
今回はニュースのみで銘柄を絞ったポートフォリオとしたため、大型株に偏り利益率が低くなった可能性があるのかもしれません。
とりあえず、利益がマイナスとならなかっただけよかったです。
案外、利益率は低いですが手堅いポートフォリオになっているのかもしれません。
(追記)
最終的に提出したモデルは8位に入賞することができました。
テスト期間のリーダーボードは再開に近い順位からかなり挽回して私自身でも驚きでした。
SIGNATEから総評で提出したモデルの特徴が紹介されておりましたが、今回作成したモデルは構築時の狙い通り、リスクを可能な限り回避、手堅くリターンを積み重ねるものになっておりました。
機会があれば振り返りに関する記事を投稿したいと思います。
まとめ
今回はニュースの定性情報のみを利用してポートフォリオ構築を試みました。
そして、構築したポートフォリオをコンペに投稿するところまで実施しました。
リーダーボードの結果は悲惨なものとなってしまいましたが、コンペ参加時に設定した当初目的は達成できたのではないかと思います。
また、コンペを通して自然言語処理について理解が深まった気がします。
本コンペではニュースデータが一年分しか提供されていなかったのでより長い期間のデータを利用した分析などしてみたいと思いました。
ただ、今回のようにテキストデータを前処理しているケースは稀ので、プライベートで分析していくのはいろいろと面倒なんだろうなと思っております。
本コンペもモデルの投稿は本日が最終日です。参加者の皆様(自分を含め)、お疲れさまでした。
ご参考
今回の記事に関するプログラムはGithub(こちら)に公開ております。
【ipynb】
- LSTM_public.ipynb:チュートリアルのLSTMの再現
- LSTM_Sector_public.ipynb:LSTM改良版の作成と検証
- BackTest_public.ipynb:バックテストの実施
【src】
- backtest_public.py:提供されたコード
【archive】
⇒ archive :今回のコンペに投稿したコード一覧
(事前学習済みモデルは容量オーバーのためアップしてません)
コメント