
前回の記事は「確率的トレンド」や「ランダムウォーク」についての理論を簡単にまとめました。
本記事では、日経平均株価がランダムウォークか検証を行いました。
理論については前回の記事をご参照ください。
今回も「Python3ではじめるシステムトレード ──環境構築と売買戦略」を参考にしております。
statsmodelsによるADF検定
これまでの他の記事と同様に、内閣府が公表している景気の分類を以下のように分けてADF検定を行います。
なお、バブル経済期については、バブルのピークまでとそれ以降に分けた場合も検証しております。
| 循環期 | 景気 | 期間-始点 | 終点 |
| 1, 2 | 戦後復興期(recover) | 1949/5/16 | 1954/11/30 |
| 3, 4, 5, 6 | 高度経済成長気(growth) | 1954/12/1 | 1971/12/31 |
| 7, 8, 8, 10 | 安定期(stable) | 1972/1/1 | 1986/11/30 |
| 11 | バブル経済期(bubble) | 1986/12/1 | 1993/10/31 |
| 12, 13, 14, 15,16 | 経済変革期(reform) | 1993/11/1 | 2019/11/30 |
| 独自設定 | 新型コロナウィルス期(covid-19) | 2019/12/1 | 現在(2020/11/25) |
statsmodelでは以下について検定が行えます。今回は、1~3を対象とします。
- \(\Delta W_t = \gamma W_{t-1} + \sum^{t}_{i=1}\sigma_i W_{t-1} + w_t\)
- \(\Delta W_t = \alpha + \gamma W_{t-1} + \sum^{t}_{i=1}\sigma_i W_{t-1} + w_t\)
- \(\Delta W_t = \alpha + \beta \cdot t + \gamma W_{t-1} + \sum^{t}_{i=1}\sigma_i W_{t-1} + w_t\)
- \(\Delta W_t = \alpha + \beta \cdot t + \eta \cdot t^2+ \gamma W_{t-1} + \sum^{t}_{i=1}\sigma_i W_{t-1} + w_t\)
1. ドリフト無しモデル
ドリフト無しのモデル(1)についてADF検定を実施し、その後、各期間における回帰係数\(\gamma\)がマイナスであるか確かめます。回帰係数がプラスであると、\(\kappa\)が1より大きくなりモデルは発散してしまいます。
これらについてまとめた結果は以下の通り。
import numpy as np
import pandas_datareader as pdr
import matplotlib.pyplot as plt
%matplotlib inline
import statsmodels.api as sm
import pandas as pd
# 日経平均株価のデータを取得
N225 = pdr.DataReader('NIKKEI225', 'fred', '1949/5/16').dropna()
ln_N225 = np.log(N225) # 対数価格に変換
# 期間の設定
starts = ['1949/5/16', '1949/5/16', '1954/12/1', '1972/1/1', '1986/12/1', '1986/12/1', '1990/1/1','1993/11/1', '2019/12/1']
ends = ['2020/11/25', '1954/11/30', '1971/12/31', '1986/11/30', '1993/10/31', '1989/12/31', '1992/8/31', '2019/11/30', '2020/11/25']
# 各期間においてADF検定を実施し、p値を格納。
p_values = []
for start, end in zip(starts, ends):
p_value = sm.tsa.adfuller(ln_N225[start:end], regression='nc')[1]
p_values.append(p_value)
gamma_list = []
# 各期間ドリフト無しランダムウォークの回帰係数を算出し、格納。
for start, end in zip(starts, ends):
y = ln_N225[start:end].diff().dropna()
x = ln_N225[start:end].shift(1).dropna()
model = sm.OLS(y, x)
results = model.fit()
gamma = results.params[0]
gamma_list.append(gamma)
# dfにまとめる
names = ['全期間', '戦後復興期(recover)', '高度経済成長期(growth)', '安定期(stable)', 'バブル経済期(bubble)',
'バブルのピークまで', 'バブルのピークから谷', '経済変革期(reform)', '新型コロナウイルス期(covid-19)']
pd.options.display.precision = 4 # 小数点以下4桁に設定
df = pd.DataFrame([starts, ends, p_values, gamma_list], index=['期間始点', '終点', 'ADF p-値', 'γ'], columns=names).T
# 判定結果を加える
df['判定'] = ['X', 'X', 'X', 'X', 'X', 'X', 'X', 'X', 'X']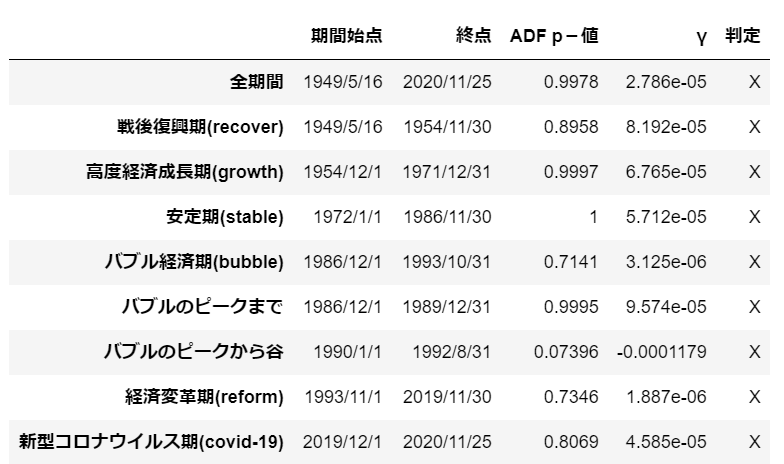
p値に着目すると、「バブルのピークから谷」以外では、帰無仮説を棄却できないです。
したがって、単純ランダムウォークという結果になりました。
しかし、最小二乗法でγを推定すると、「バブルのピークから谷」以外ではすべてプラスであることから、単純ランダムウォークである可能性である期間は見つからなかったです。
2.ドリフト付きモデル
上記と同様の手順でドリフト付きモデルでADF検定を実施しました。
sm.tsa.adfuller()の引数regression=’c’にするだけでドリフト付きモデルによるADF検定となります。また、今回の最小二乗法では、切片を追加している点が先ほどの検証と異なります。
# ドリフト付きモデル
# 各期間においてADF検定を実施し、p値を格納。
p_values = []
for start, end in zip(starts, ends):
p_value = sm.tsa.adfuller(ln_N225[start:end], regression='c')[1] # c:ドリフト付き
p_values.append(p_value)
const_list = []
gamma_list = []
# 各期間ドリフト付きモデルの回帰係数を算出し、格納。
for start, end in zip(starts, ends):
y = ln_N225[start:end].diff().dropna()
x = ln_N225[start:end].shift(1).dropna()
x = sm.add_constant(x) # 切片(ドリフト)を追加
model = sm.OLS(y, x)
results = model.fit()
const = results.params[0]
gamma = results.params[1]
# 回帰係数を保存
const_list.append(const)
gamma_list.append(gamma)
df = pd.DataFrame([starts, ends, p_values, gamma_list, const_list], index=['期間始点', '終点', 'ADF p-値', 'γ', '切片'], columns=names).T
# 判定結果を加える
df['判定'] = ['△', 'OK', 'OK', 'OK', 'OK', 'OK', 'OK', 'OK', 'OK']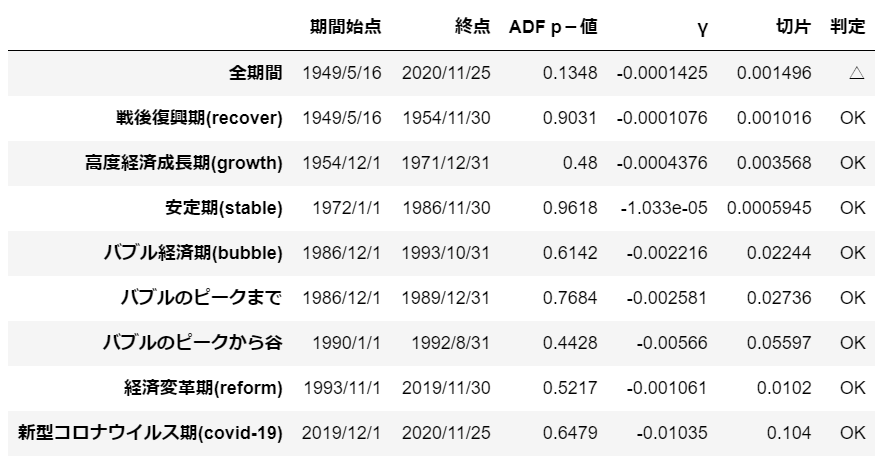
「全期間」を除いて、ドリフト付きモデルでランダムウォークの可能性があります。
「全期間」のp値は13.5%と他の期間に比べ低かった為、判定結果を”△”としました。
ドリフト+時間付きモデル
最後にドリフト付き+時間付きモデルでADF検定を実施します。
sm.tsa.adfuller()の引数regression=’ct’にするだけで検証が可能です。
今回の最小二乗法では、時間項を追加している点が先ほどとは異なります。
# ドリフト付きモデル
# 各期間においてADF検定を実施し、p値を格納。
p_values = []
for start, end in zip(starts, ends):
p_value = sm.tsa.adfuller(ln_N225[start:end], regression='ct')[1] # ct:ドリフト+時間付き
p_values.append(p_value)
const_list = []
gamma_list = []
beta_list = []
# 各期間においてドリフト+時間付きモデルの回帰係数を算出し、格納。
for start, end in zip(starts, ends):
y = ln_N225[start:end].diff().dropna()
x = ln_N225[start:end].shift(1).dropna()
x = sm.add_constant(x) # 切片(ドリフト)を追加
x['time'] = range(len(y)) # 時間項を追加
model = sm.OLS(y, x)
results = model.fit()
const = results.params[0]
gamma = results.params[1]
beta = results.params[2]
# 回帰係数を保存
const_list.append(const)
gamma_list.append(gamma)
beta_list.append(beta)
df = pd.DataFrame([starts, ends, p_values, gamma_list, const_list, beta_list], index=['期間始点', '終点', 'ADF p-値', 'γ', '切片', '時間'], columns=names).T
# 判定結果を加える
df['判定'] = ['OK', 'OK', 'OK', 'OK', 'OK', 'OK', 'OK', 'OK', 'OK']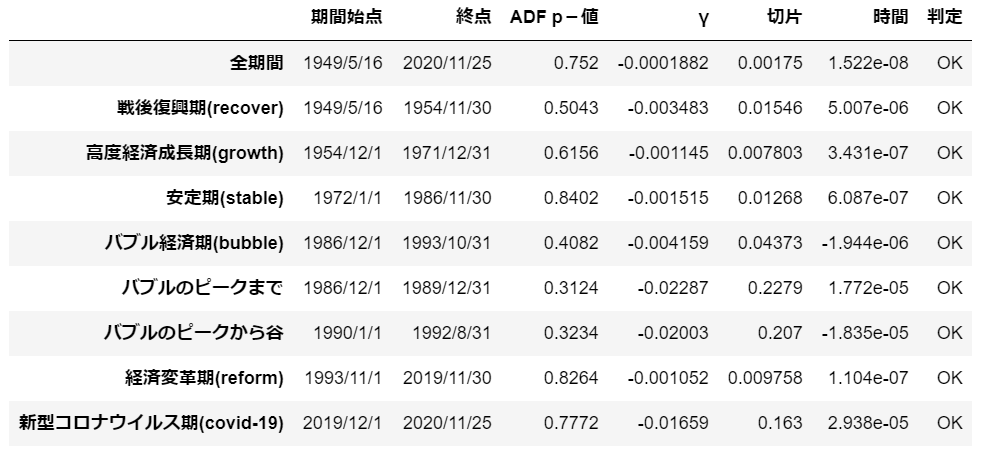
結果として、すべての期間でドリフト+時間付きモデルでランダムウォークである可能性があることが示されました。
まとめ
今回は、日経平均株価がランダムウォークであるか検証をしてみました。
結果としては、ほとんどでランダムウォークである可能性が示されました。
ランダムウォークの場合、株価の予測は困難と思われます。
ランダムウォークの世界で勝負しても確率50%の運任せになってしまう為、ランダムウォーク性が成り立たないようなフィールドを見つけなけれならないのかもしれないです。
例えば、今回の検証では、景気ごとに期間を分けていますが、更に期間を短くしてみたり、時間軸を変更してみたり、対象を個別銘柄にしてみると良いのかもしれないです。
効率的市場仮説が成立しないようなフィールドの探索が必要になってくるのかもしれないです。


コメント